Mysql安装
检验是否安装
命令行提示

cmd中验证
mysql -u root -p
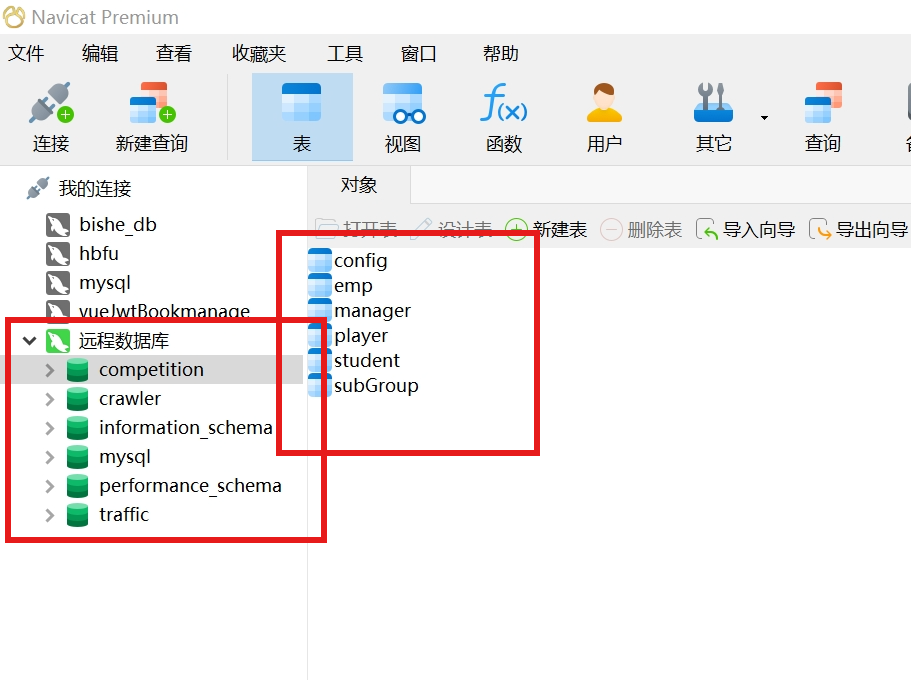
navicat17连接远程的数据库
输入地址及密码,使用navicat17
tomcat安装
我的tomcat目录
D:\tomcat\apache-tomcat-8.5.57
如何创建表
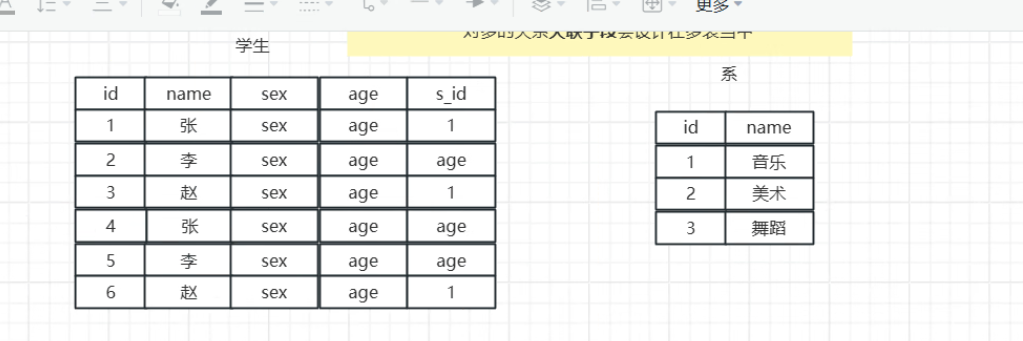
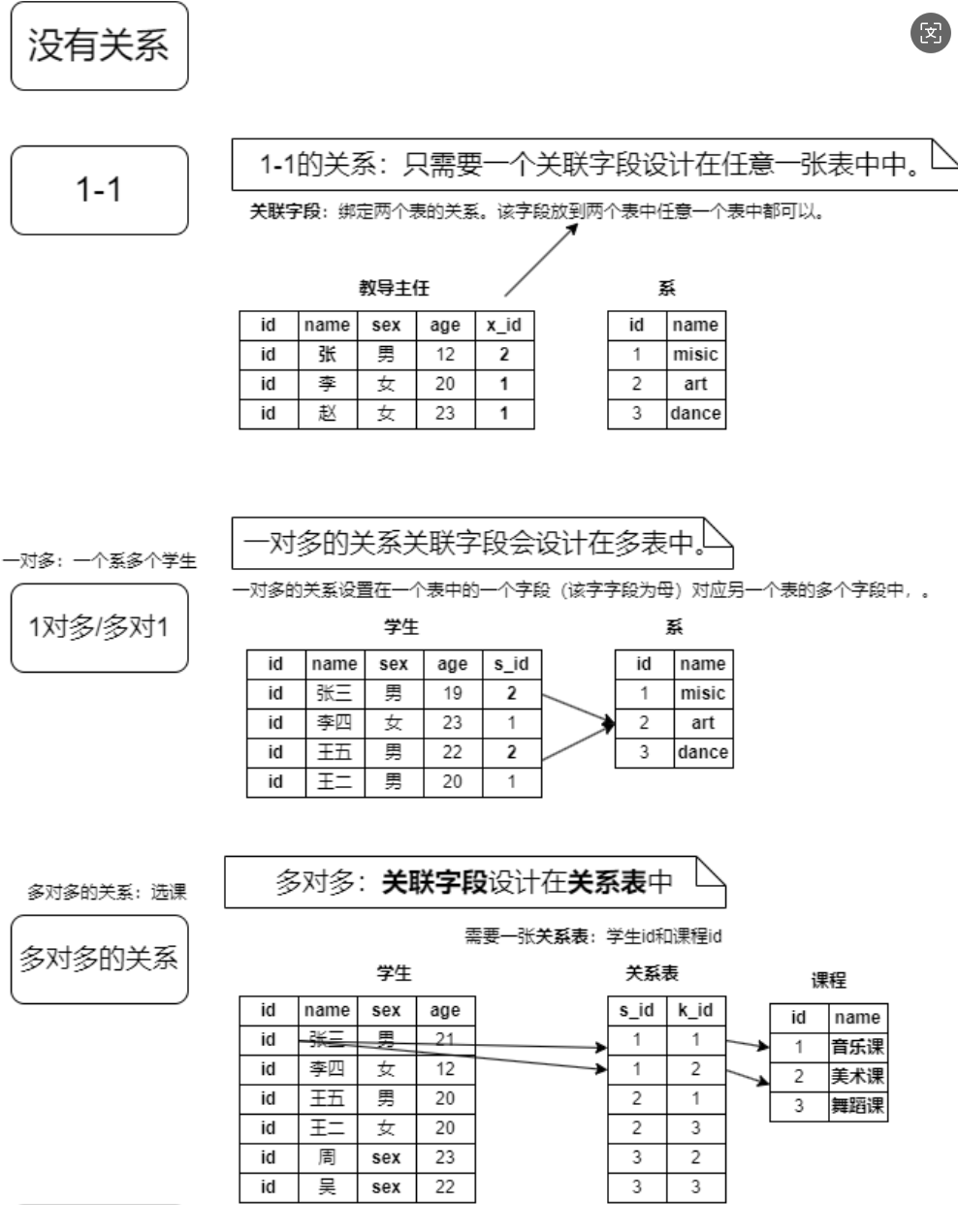
一、了解表和表之间的关系
四种关系:
- 没有关系
- 一对一
- 1对多或多对1
- 多对多
关联字段可以设置在任意的一张表中
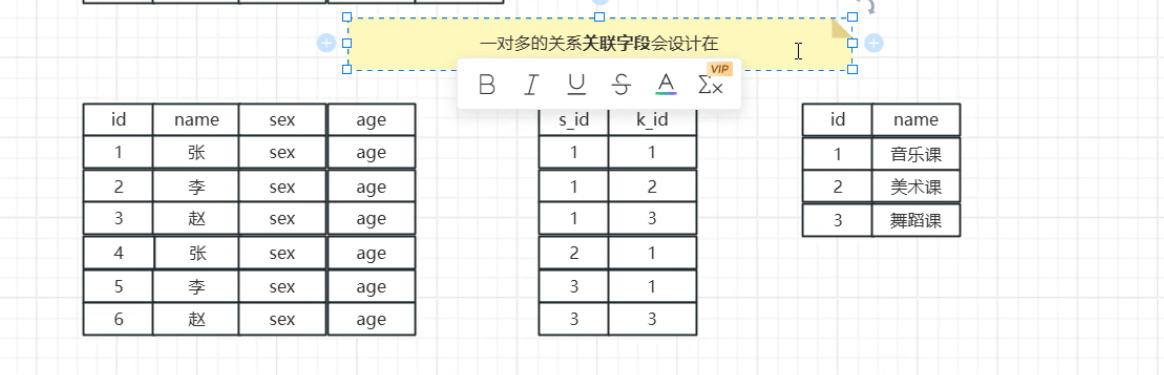
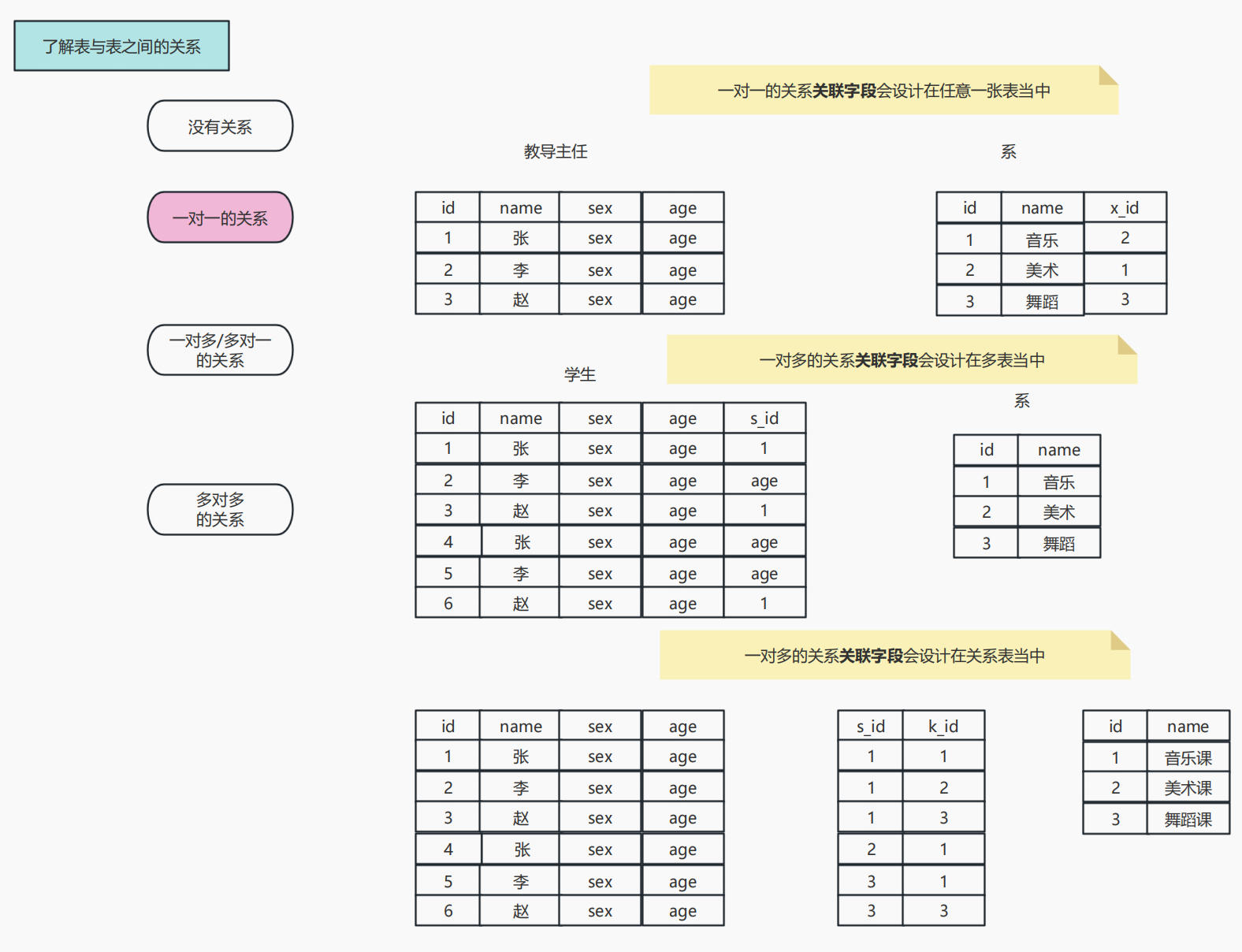

这里的多表指的是:多对一的关系。
SQL语句
新建数据库

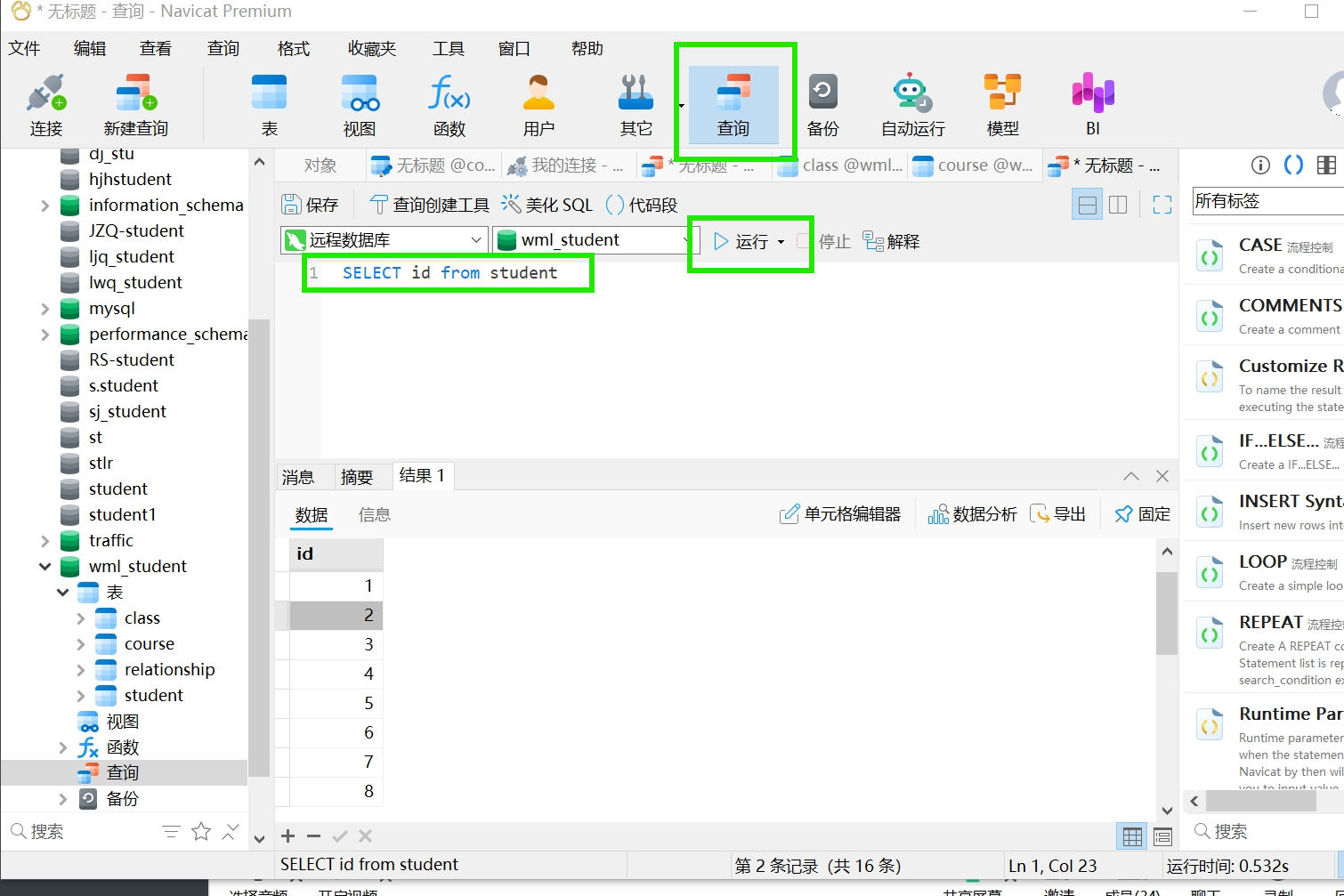
全选、运行、刷新
DROP TABLE IF EXISTS `class`;
CREATE TABLE `class` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`class_num` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '班级号',
`class_name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '班级名称',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Compact;
-- ----------------------------
-- Records of class
-- ----------------------------
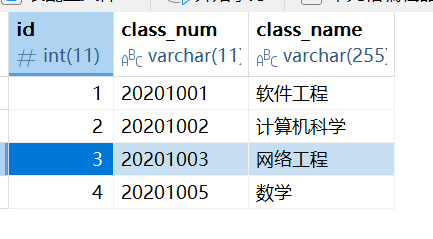
INSERT INTO `class` VALUES (1, '20201001', '软件工程');
INSERT INTO `class` VALUES (2, '20201002', '计算机科学');
INSERT INTO `class` VALUES (3, '20201003', '网络工程');
INSERT INTO `class` VALUES (4, '20201005', '数学');
-- ----------------------------
-- Table structure for course
-- ----------------------------
DROP TABLE IF EXISTS `course`;
CREATE TABLE `course` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '选课表',
`cno` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '课程号',
`gradeName` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '课程名称',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Compact;
-- ----------------------------
-- Records of course
-- ----------------------------
INSERT INTO `course` VALUES (1, '1001', '数学');
INSERT INTO `course` VALUES (2, '1002', '语文');
INSERT INTO `course` VALUES (3, '1003', '英语');
-- ----------------------------
-- Table structure for relationship
-- ----------------------------
DROP TABLE IF EXISTS `relationship`;
CREATE TABLE `relationship` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`sno` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '学号',
`cno` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '课程号',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 39 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Compact;
-- ----------------------------
-- Records of relationship
-- ----------------------------
INSERT INTO `relationship` VALUES (1, '202001', '1001');
INSERT INTO `relationship` VALUES (2, '202001', '1002');
INSERT INTO `relationship` VALUES (3, '202001', '1003');
INSERT INTO `relationship` VALUES (4, '202002', '1001');
INSERT INTO `relationship` VALUES (5, '202002', '1002');
INSERT INTO `relationship` VALUES (6, '202003', '1003');
INSERT INTO `relationship` VALUES (7, '202004', '1001');
INSERT INTO `relationship` VALUES (8, '202004', '1002');
INSERT INTO `relationship` VALUES (9, '202004', '1003');
INSERT INTO `relationship` VALUES (10, '202005', '1001');
INSERT INTO `relationship` VALUES (11, '202005', '1002');
INSERT INTO `relationship` VALUES (12, '202006', '1003');
INSERT INTO `relationship` VALUES (13, '202006', '1001');
INSERT INTO `relationship` VALUES (14, '202006', '1002');
INSERT INTO `relationship` VALUES (15, '202007', '1003');
INSERT INTO `relationship` VALUES (16, '202009', '1001');
INSERT INTO `relationship` VALUES (17, '202009', '1002');
INSERT INTO `relationship` VALUES (18, '202009', '1003');
INSERT INTO `relationship` VALUES (19, '202010', '1001');
INSERT INTO `relationship` VALUES (20, '202010', '1002');
INSERT INTO `relationship` VALUES (21, '202010', '1003');
INSERT INTO `relationship` VALUES (22, '202011', '1001');
INSERT INTO `relationship` VALUES (23, '202012', '1002');
INSERT INTO `relationship` VALUES (24, '202012', '1003');
INSERT INTO `relationship` VALUES (25, '202013', '1001');
INSERT INTO `relationship` VALUES (26, '202013', '1002');
INSERT INTO `relationship` VALUES (27, '202014', '1003');
INSERT INTO `relationship` VALUES (28, '202014', '1001');
INSERT INTO `relationship` VALUES (29, '202014', '1002');
INSERT INTO `relationship` VALUES (30, '202015', '1003');
INSERT INTO `relationship` VALUES (31, '202015', '1001');
INSERT INTO `relationship` VALUES (32, '202016', '1002');
INSERT INTO `relationship` VALUES (33, '202016', '1003');
-- ----------------------------
-- Table structure for student
-- ----------------------------
DROP TABLE IF EXISTS `student`;
CREATE TABLE `student` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL,
`sex` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL,
`age` int(11) NOT NULL,
`sno` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin NOT NULL COMMENT '学号',
`class_num` varchar(11) CHARACTER SET utf8mb4 COLLATE utf8mb4_bin DEFAULT NULL COMMENT '班级号',
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 17 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_bin ROW_FORMAT = Compact;
-- ----------------------------
-- Records of student
-- ----------------------------
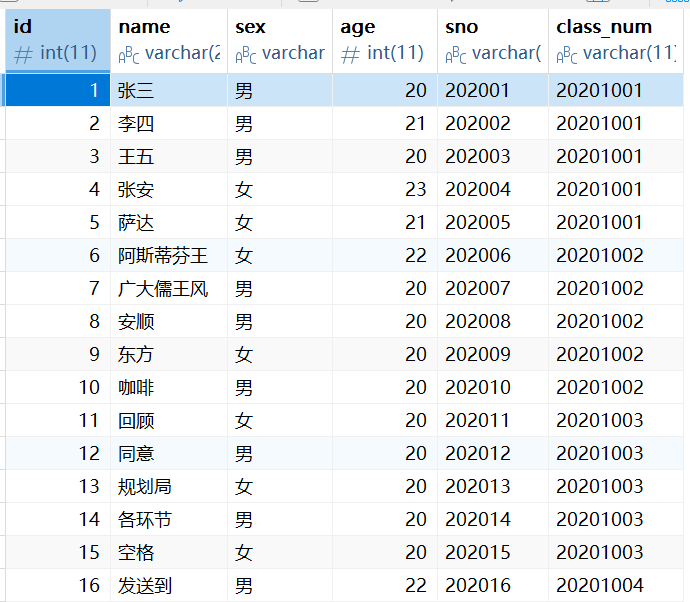
INSERT INTO `student` VALUES (1, '张三', '男', 20, '202001', '20201001');
INSERT INTO `student` VALUES (2, '李四', '男', 21, '202002', '20201001');
INSERT INTO `student` VALUES (3, '王五', '男', 20, '202003', '20201001');
INSERT INTO `student` VALUES (4, '张安', '女', 23, '202004', '20201001');
INSERT INTO `student` VALUES (5, '萨达', '女', 21, '202005', '20201001');
INSERT INTO `student` VALUES (6, '阿斯蒂芬', '女', 22, '202006', '20201002');
INSERT INTO `student` VALUES (7, '广大儒风', '男', 20, '202007', '20201002');
INSERT INTO `student` VALUES (8, '安顺', '男', 20, '202008', '20201002');
INSERT INTO `student` VALUES (9, '东方', '女', 20, '202009', '20201002');
INSERT INTO `student` VALUES (10, '咖啡', '男', 20, '202010', '20201002');
INSERT INTO `student` VALUES (11, '回顾', '女', 20, '202011', '20201003');
INSERT INTO `student` VALUES (12, '同意', '男', 20, '202012', '20201003');
INSERT INTO `student` VALUES (13, '规划局', '女', 20, '202013', '20201003');
INSERT INTO `student` VALUES (14, '各环节', '男', 20, '202014', '20201003');
INSERT INTO `student` VALUES (15, '空格', '女', 20, '202015', '20201003');
INSERT INTO `student` VALUES (16, '发送到', '男', 22, '202016', '20201004');
SET FOREIGN_KEY_CHECKS = 1;
sql语句中不区分大小写
sql语句关键字必须写在最前面
一、查询语句—select
- select关键字
- select 查询字段 from 查询的表
#查询
select id from student
select id,name from stdent
select id,name,sex from student
#查询所有字段
select * from student

(1)条件查询—>where
-
关键字:where
-
运算符 说明 = 等于 <>或!= 不等于 < 小于 <= 小于等于 > 大于 >= 大于等于 between..and… 两个值之间 is null 为null and 并且 or 或者 in 包含 not not可以取非,主要用在is或in like like为模糊查询,支持%或_匹配
#查询
select * from student where class_num = '20201001'
#查询id为1
select * from student where id = 1
#查询出年龄不是20岁的学生
select * from student where age <>20
select * from student where age != 20
#查询出年龄大于20岁的学生
#查询出年龄小于20岁的学生
select name from student where age < 20
#查询出年龄小于20岁的学生---》字符串类型没法比较
#查询年龄20-25岁的学生---》between...and...
#都是闭区间
select age from student where age between 21 and 23
#查询班级号为空的学生---》null
select * from student where class_num is null

#查询出班级号为20201001班的男同学---》and
select * from student where class_num = '20201001' and sex = '男'
#查询出班级号20201001班的同学和其他班的男同学
select * from student where class_num ='20201001' or sex = '男'
操作符IN、between…and
允许我们在 WHERE 子句中规定多个值
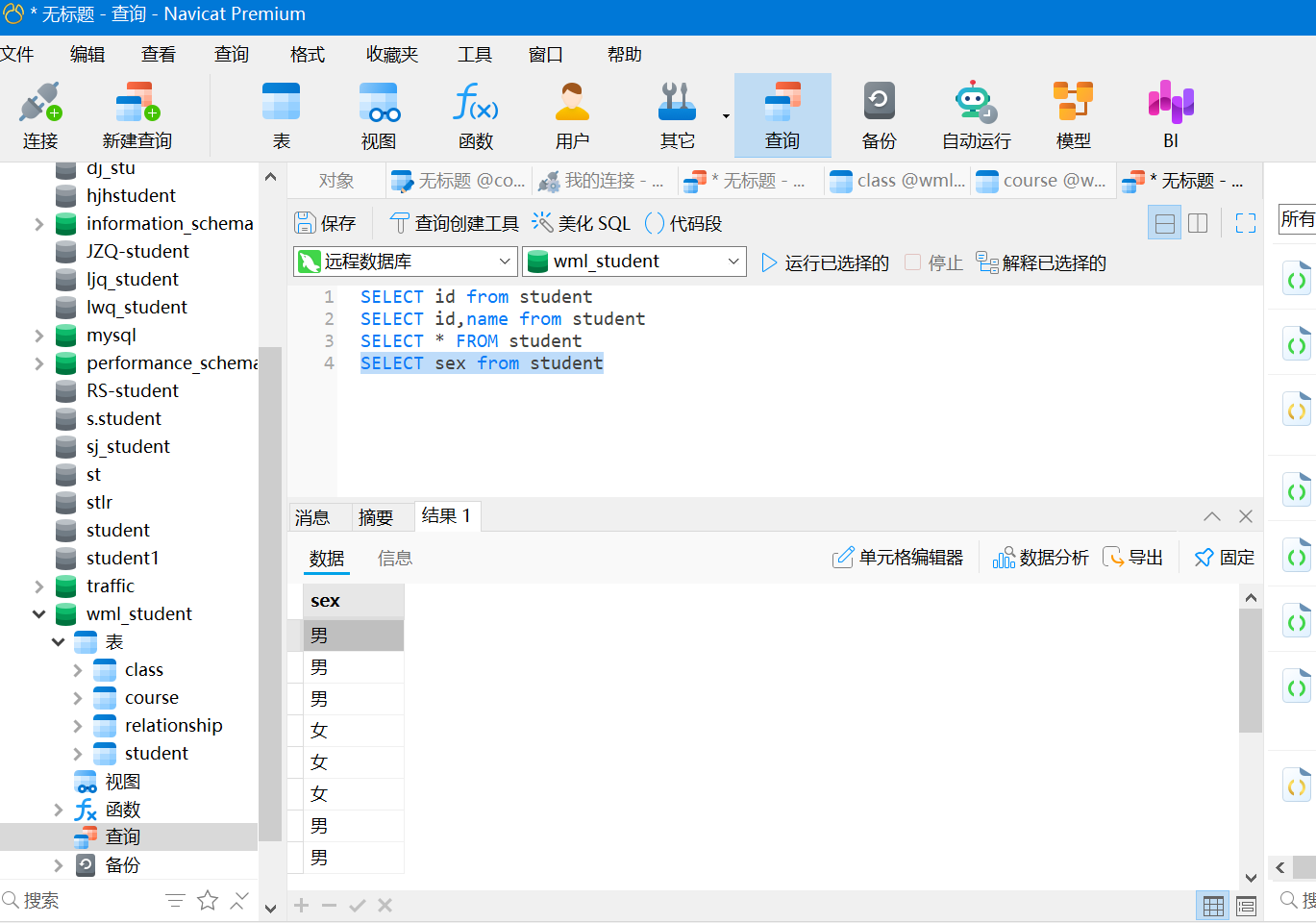
#IN操作符运行在WHere子句中规定多个值
#查询出用户id为1和3的用户记录
select * from student where id in (1,3,5,8)
模糊查询—>like和_、%
匹配字符
#_(一次匹配一个字符)%(一次匹配多个字符)
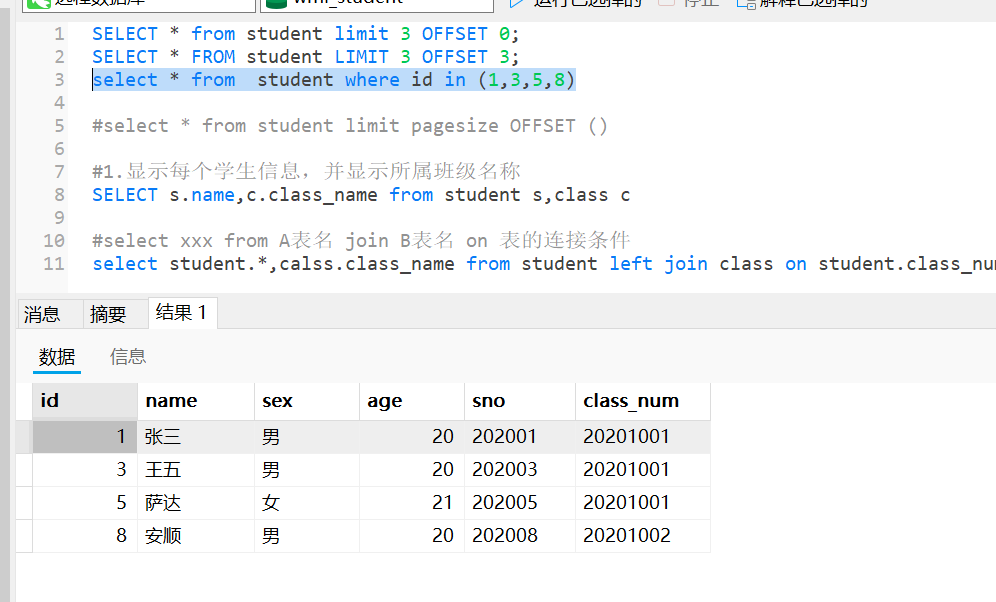
#查询出名字中带有王字的同学---》like
select * from student where name like '%王%'
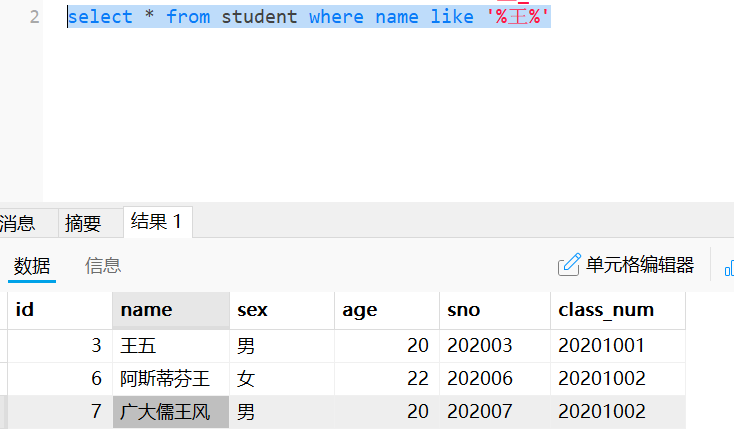
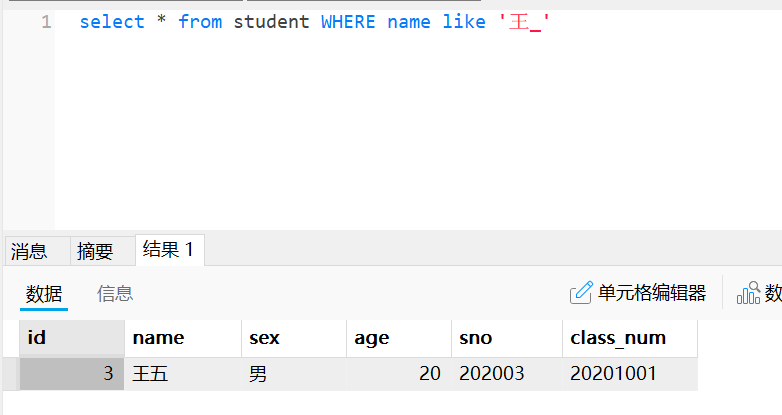
#查询出名字中带有王字开头且两个字的同学
select * from student where name like '王_'
分组函数/聚合函数
| sum | 求和 |
|---|---|
| avg | 取平均 |
| max | 取最大值 |
| min | 取最小值 |
| count | 取得记录数 |
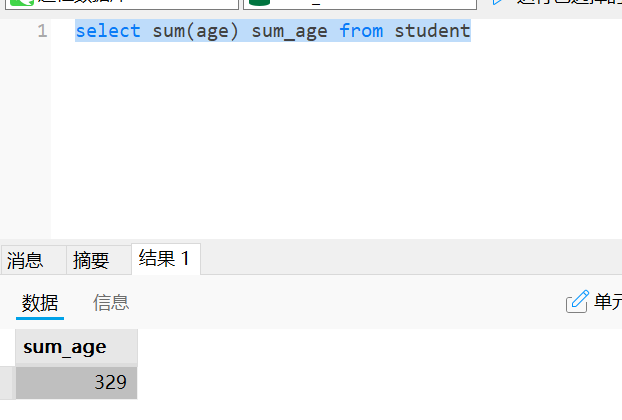
#求学生年龄的总和
select sum(age) sum_age from student
#查询出所有学生的平均年龄
select avg(age) avg_age from student
#查询出年龄最大的同学
select max(age) from student;
select min(age) from student;
#查询所有学生的数量
select count(*) from student;
select count(class_num) from student;
#列别名
select count(class_num) class_result from student;
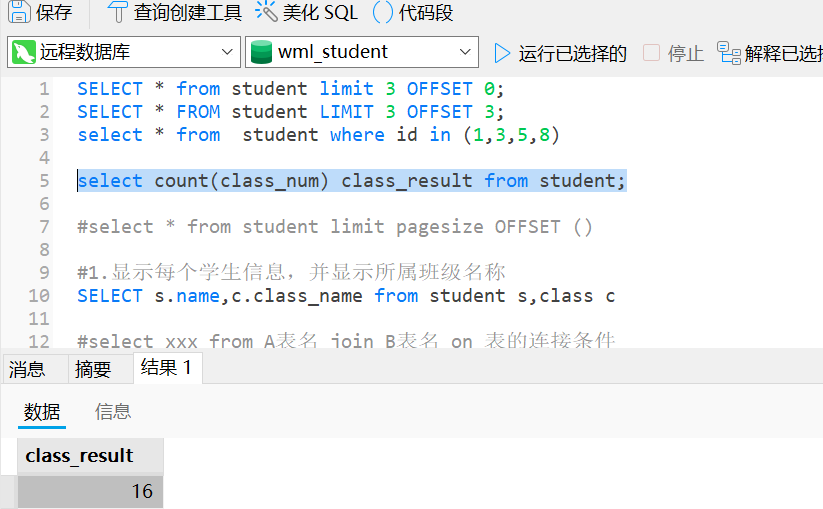
注意:count(*)表示去取得查询表的所有记录,count(字段名),不会统计为null的记录。
(2)分组查询group by
作用:通过那个或那些字段进行分组
- 用法:group by 字段名称
#求各个班级的平均年龄-->按照班级分组
select class_num,avg(age) from student GROUP BY class_num
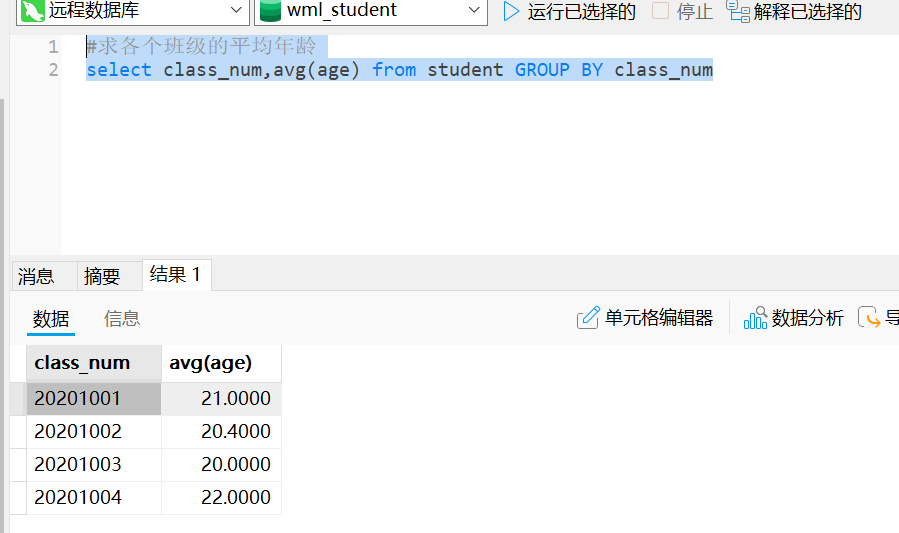
结果列指定了一个别名
#求各个班级的平均年龄
select class_num,avg(age) avg_result from student GROUP BY class_num
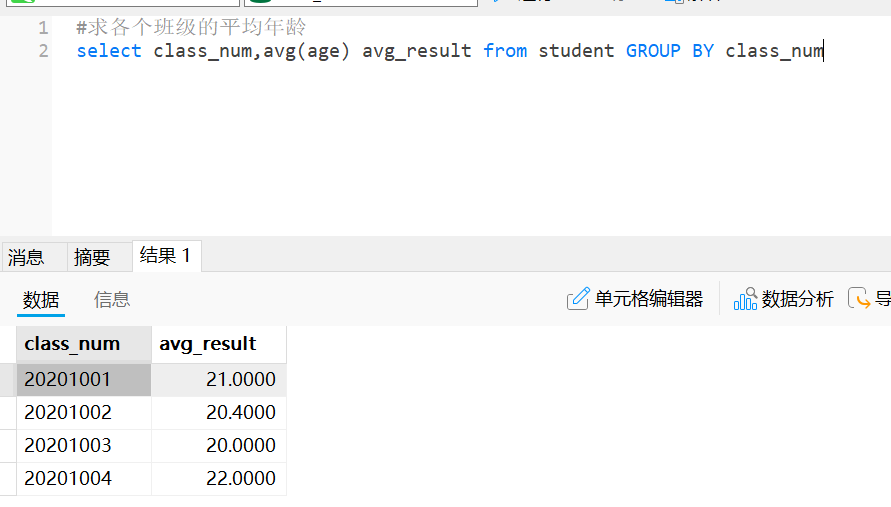
(3)排序order by 和倒序desc
select查询的结果默认的是按照从小到大排序的,而且是以id为主列进行从大到小排序的。也就是根据主键排序。
要根据其他条件排序如何做?
查询排序的关键字:order by
#按照年龄正序排列
SELECT * from student ORDER BY age;
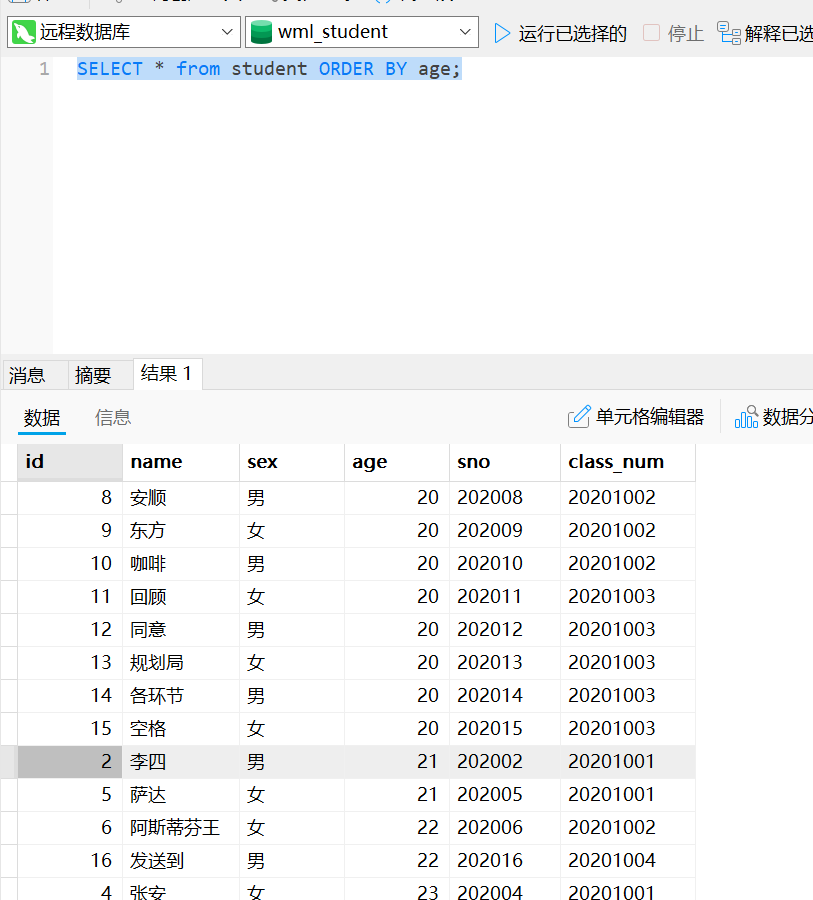
desc表示“倒序”
#按照年龄倒序排列
select * from student ORDER BY age DESC
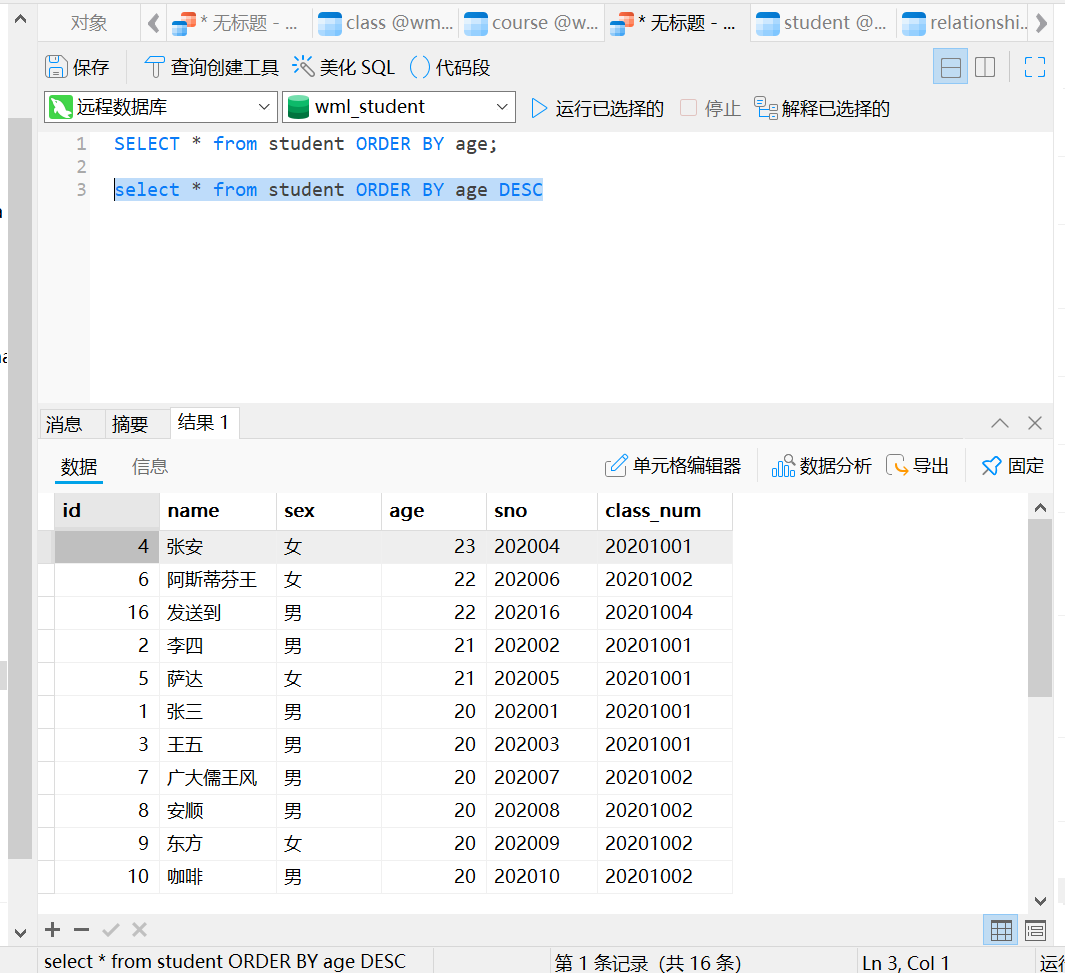
年龄降序且学号升序
如果要按照年龄降序,并且按照学号升序怎么做?
-
也就是说
-
首先按照
age从大到小排序(23, 22, 22, 20, 20)。然后在相同
age的情况下,按照sno从小到大排序(例如,202006在 `202016 之前,因为 006 < 016)。
#简化写法
SELECT * FROM student ORDER BY age DESC, sno;
#完整写法 多了ASC
SELECT * FROM student ORDER BY age DESC, sno ASC;
#易于读的写法
SELECT *
FROM student
ORDER BY age DESC, sno ASC;
(4)分页查询/限制查询
使用SELECT查询时,如果结果集数据量很大,比如几万行数据,放在一个页面显示的话数据量太大,不如分页显示,每次显示100条。
要实现分页功能,实际上就是从结果集中显示第1100条记录作为第1页,显示第101200条记录作为第2页,以此类推。
因此,分页实际上就是从结果集中“截取”出第M~N条记录。这个查询可以通过LIMIT OFFSET 子句实现。
limit限制查询
首先,先查询结果中的前三条数据。
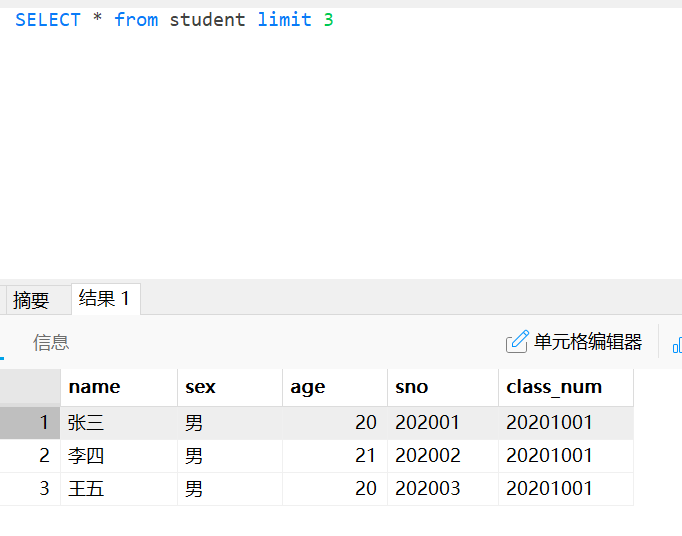
LIMIT OFFSET分页
然后,把结果集分页,每页三条记录,那么获取第一条记录:
#LIMIT 3 OFFSET 0表示,对结果集从0号记录开始,最多取3条。注意SQL记录集的索引从0开始。**
SELECT * from student LIMIT 3 offset 0;
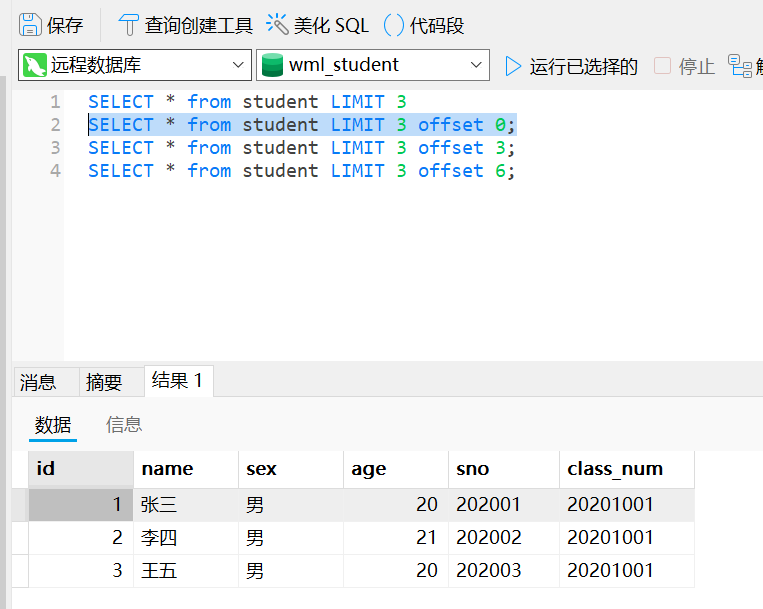
如果要查询第2页,那么我们只需要“跳过”头3条记录,也就是对结果集从3号记录开始查询,把OFFSET设定为3:
#对结果集从第3号记录开始,最多取3条。
SELECT * from student LIMIT 3 offset 3;
关键点
可见,分页查询的关键在于,首先要确定每页需要显示的结果数量pageSize(这里是3),然后根据当前页的索引pageIndex(从1开始),确定LIMIT和OFFSET应该设定的值:
- LIMIT总是设定为pageSize
- OFFSET计算公式为pageSize * (pageIndex - 1)
很好理解
简化写法

SELECT * from student LIMIT 0,3;
#对结果集从3号记录开始,最多取3条
SELECT * from student LIMIT 3,3;
#对结果集从3号记录开始,最多取6条
SELECT * from student LIMIT 3,6;
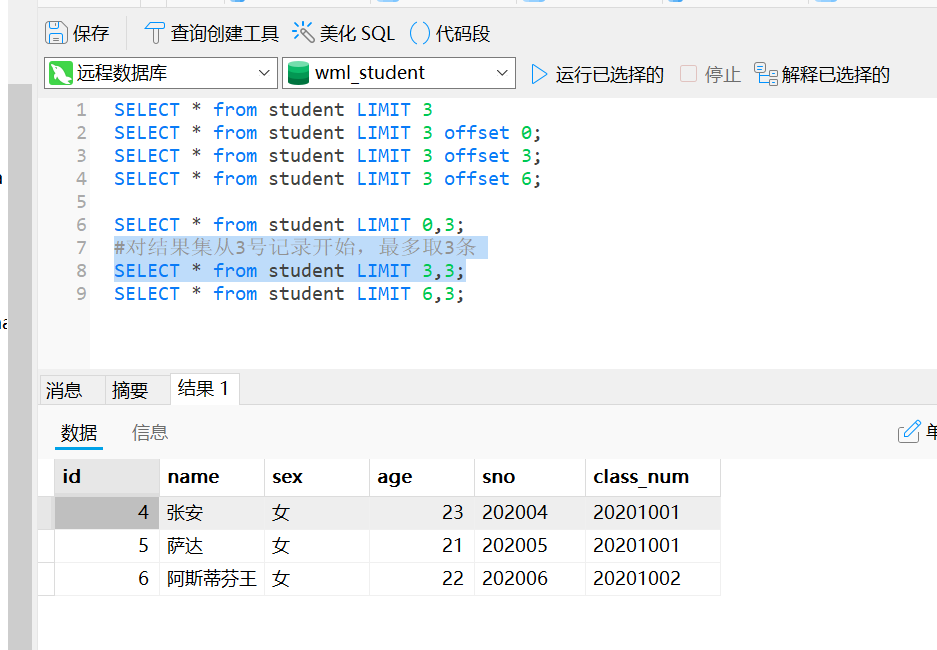
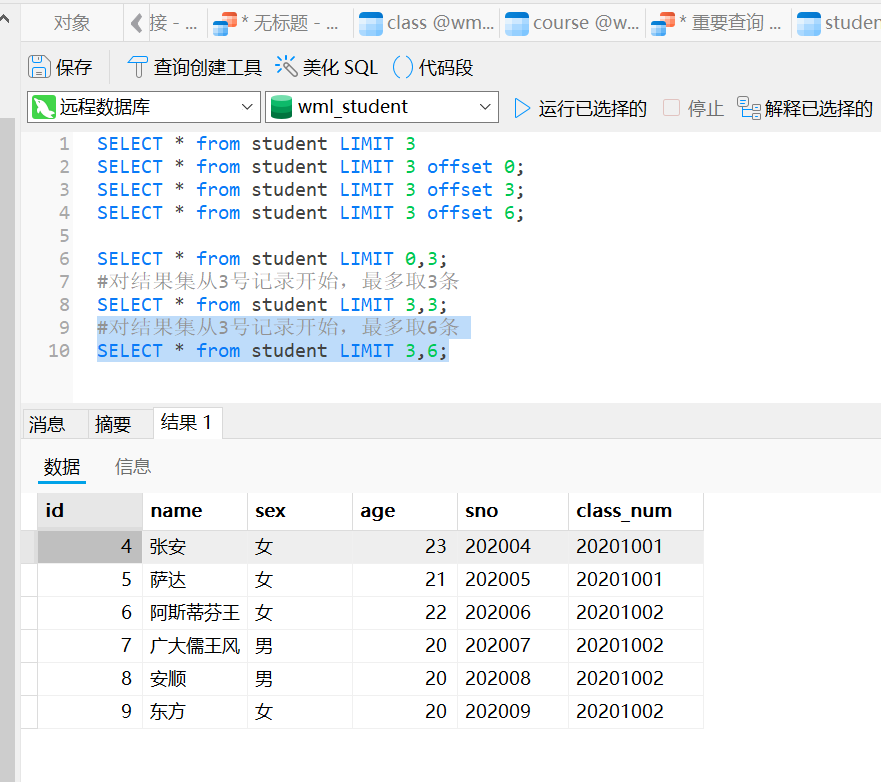
小结
使用LIMIT OFFSET 可以对结果集进行分页,每次查询返回结果集的一部分;
分页查询需要先确定每页的数量和当前页数,然后确定LIMIT和OFFSET的值。
(5)连表查询/跨表查询
在实际开发中,数据往往不是存放一张表中,而是同时存储在多张表中,这些表与表存在着关系,我们在检索数据的时候往往需要多张表联合起来检索,这种多表联合检索被称为连表查询或跨表查询。
-
笛卡尔积现象
含义:若两张表进行连接查询的时候没有任何条件限制,最终的查询结果总数是两张表记录的成绩,该现象称为笛卡尔积现象。
1.左/右外连接
首先,student表
class表
要查询每个学生的班级名称?
- 可以看到学生表中,只有班级编号,没有班级名称。而班级表中有班级编号和班级名称。共同点是班级编号。
这就是班级名称的数据在student表中找不到,需要用到class表,那么不是存放一张表中,而是同时存储在2张表中,那么需要联合起来搜索。
- 1.SQL92语法 select xxx from A 表名,B表名 where 表连接条件 and 数据查询条件;(读者可以跳过不看)
SELECT s.name,c.class_name from student s,class c where s.class_num = c.class_num
- 缺点:表连接条件与查询条件放在一起,没有分离
2.SQL99语法
select xxx from A 表名 join B 表名 on 表的连接条件
#查询每个学生的班级名称--->左连接
SELECT student.*,class.class_num from student left JOIN class ON student.class_num = class.class_num
优点:表连接独立,结构清晰,如果结果数据不满足要求,可再追加where条件进行过滤;
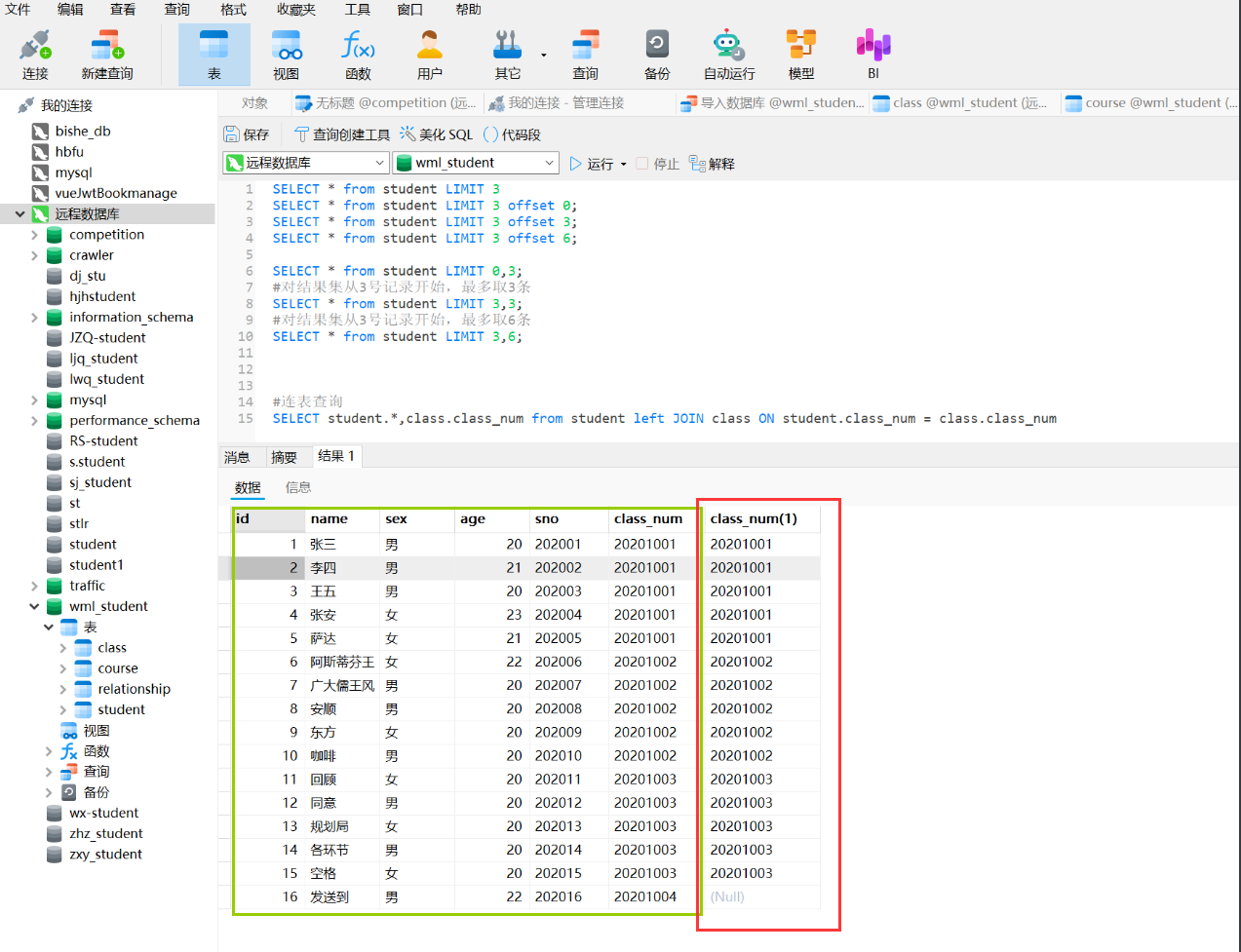
从查询结果可以看到,绿色部分全都是student表,class_num(1)是class表中的class_num自动生成的列。(也可以设置别名)
同理右连接:
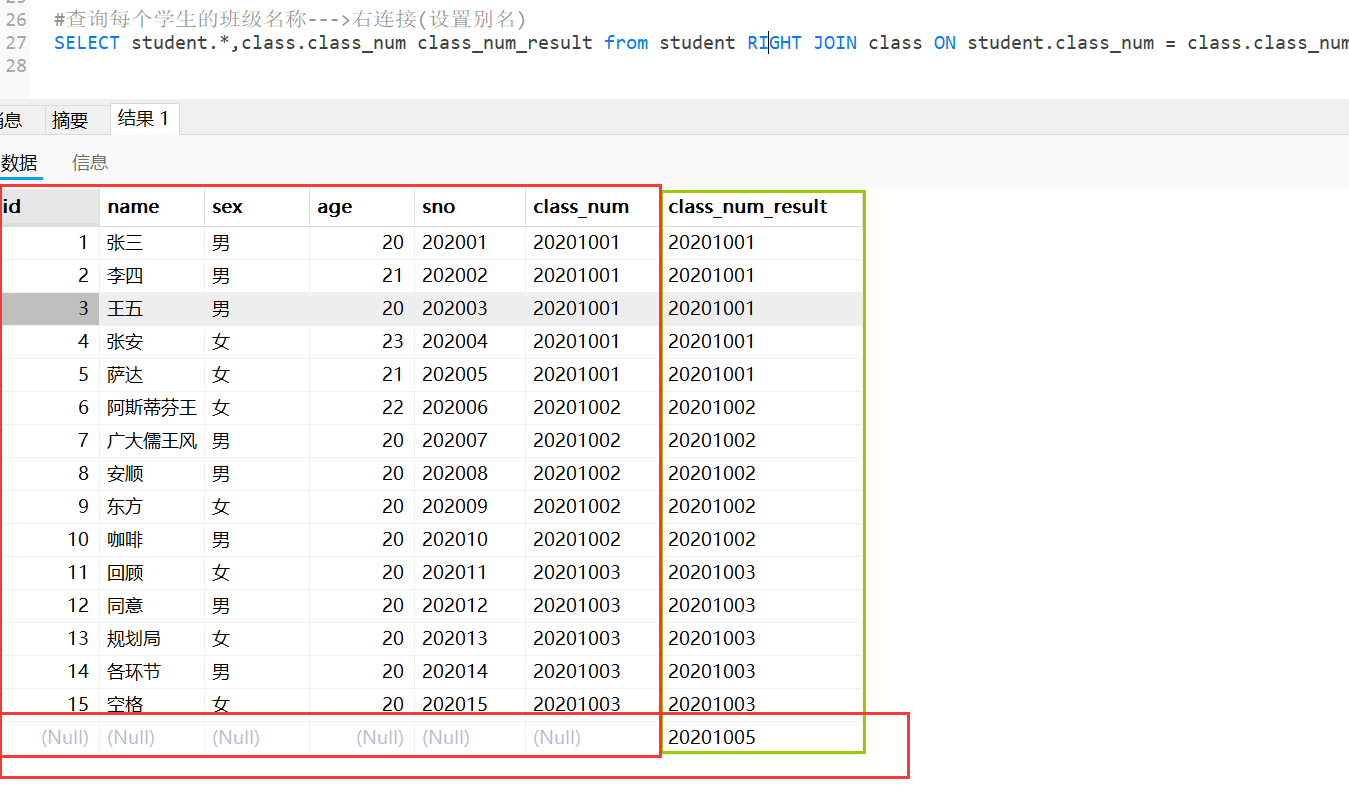
结果分析(重点):
查询每个学生的班级名称,即使某些学生没有对应的班级(不保留班级)。
左连接:class有class_num为20021001-03和05的班级,student的class_num只有01-04的学生。左表student的全部记录,与右表class不匹配的部分为Null。
查询每个班级的学生,即使某些班级没有对应的学生(不保留学生)
右连接:student的class_num有01-04的学生,class的class_num有01-03和05的班级。保留右表课程表的全部记录,与左表不匹配的部分为Null。
设置别名
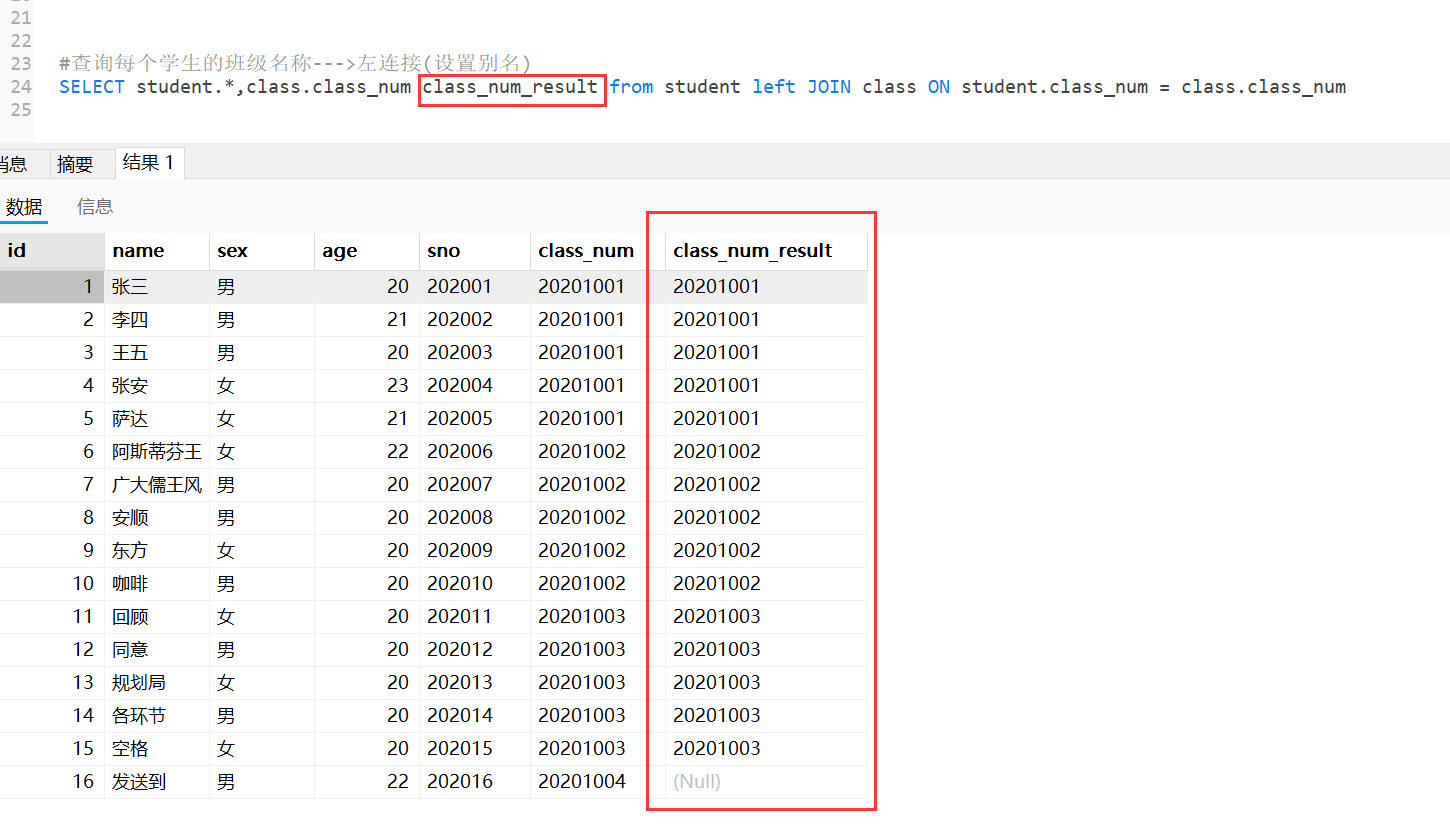
总结:
左连接(LEFT JOIN):以左表为基准,保留左表的所有记录,右表中匹配的记录显示,不匹配的部分为 NULL。
右连接(RIGHT JOIN):以右表为基准,保留右表的所有记录,左表中匹配的记录显示,不匹配的部分为 NULL。
小总结:连接其实就是将两个表放在一起成为一个表,然后进行select进行查询
SELECT 你想要结果中出现的字段(不一定结果中都需要出现两个表的字段) from student 连接方式 class ON 两张表中的相同或相关的字段(如主键和外键)
肯定有个疑问,on后的关系是什么?两张表是否必须有相同的字段才能使用连接?
不一定。虽然在大多数情况下,连接条件基于两张表中的相同或相关的字段(如主键和外键),但两张表不需要有完全相同的字段才能进行连接。关键在于找到能够建立逻辑关联的字段。
on后的关系是什么呢?
首先要了解一下一个表可以包含哪些字段:
关系型数据库的字段分类
关系型数据库中,一个表可以包含以下几类字段:
主键:用于唯一标识表中的每一条记录,每个表必须有一个主键。
-
用于唯一标识表中的每一条记录。
-
每个表通常有一个主键,可以是单一字段(如
id)或由多个字段组成的复合主键。 -
主键的值必须唯一且不能为空(
NOT NULL)。
外键:用于建立与其他表的关联关系,确保数据的参照完整性,一个表可以有多个外键,也可以没有外键。
-
用于在一个表中引用另一个表的主键,从而建立两个表之间的关系。
-
外键可以帮助维护数据的参照完整性,确保引用的数据在被引用的表中存在。
其他
非键字段:用于存储与实体相关的其他信息,不参与表之间的关联。
-
这些字段既不是主键也不是外键,用于存储与实体相关的其他信息。
-
例如,在学生表中,
name、age、address等字段就是非键字段。
区分on后的关系和外键:
on后一定是外键吗?
外键必须是引用主键建立两个表之间建立关系的键,****
on后是两个表之间建立关系的字段,在两表连接的时候,on后的字段有可能是外键,也就是使用了一个表中的主键。
所以on后的关系可以是:
两个表之间相同的字段、可能是主键也可能是非键字段
两个表之间不同的字段,可以完全不同。
例如:
一、完全不相同的字段
course表

student表
完全没有相同的字段。
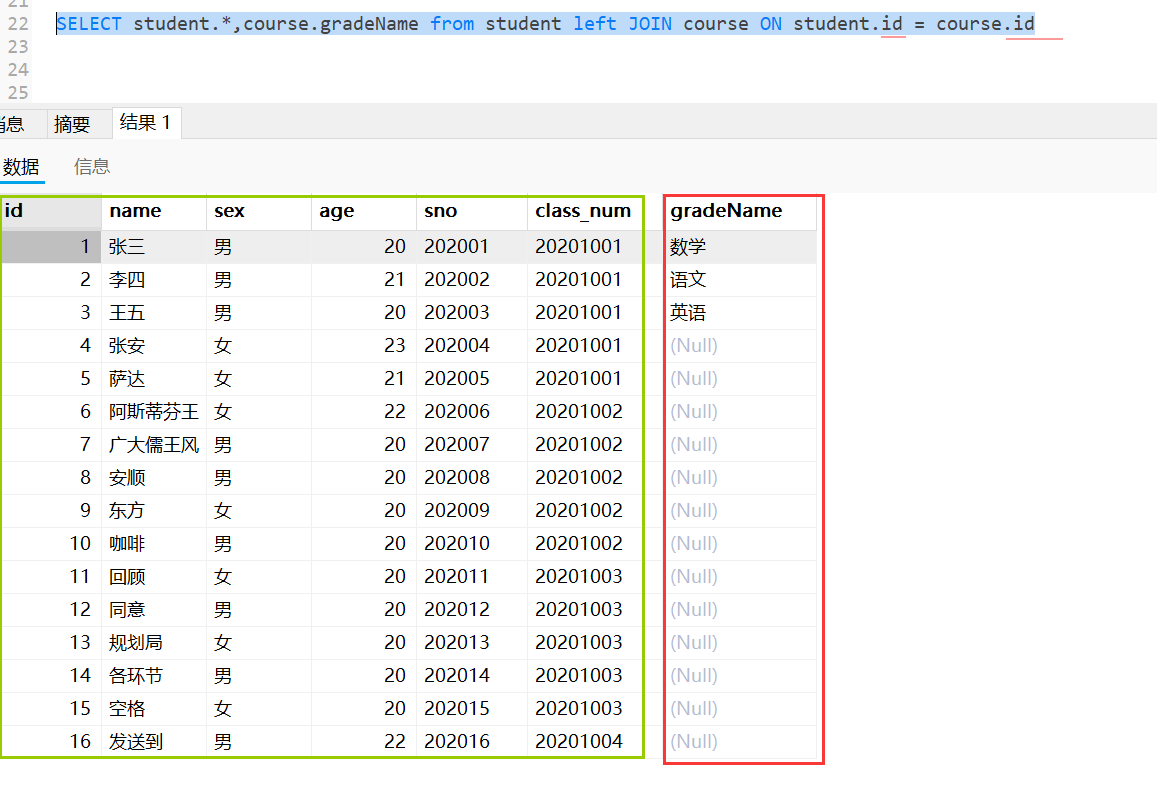
这里使用student.class_num = course.gradeName作为on后的条件,显然两者完全不相同。
#连表查询-->on后的字段完全不同
SELECT student.*,course.gradeName from student left JOIN course ON student.class_num = course.gradeName
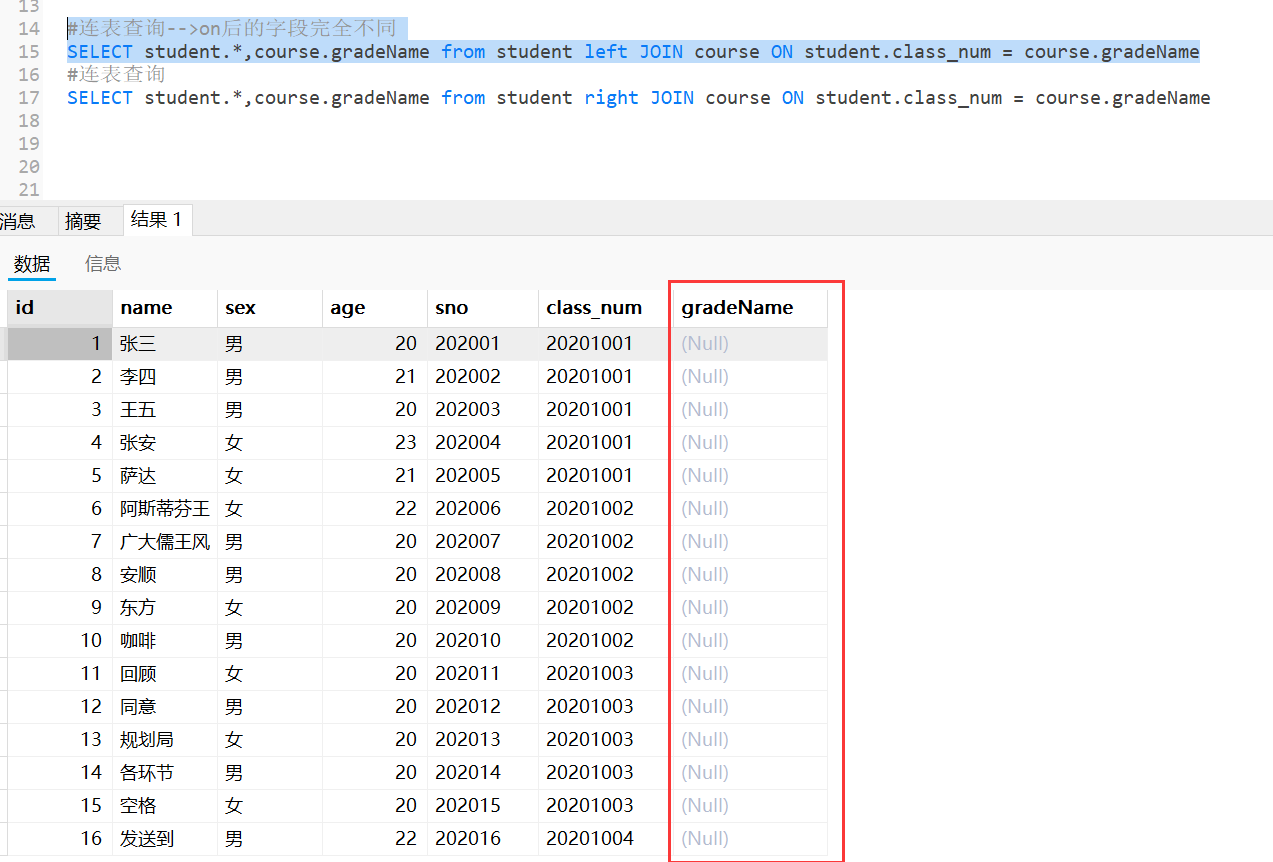
左连接后,以student为主表,查询出gradeName,一个都没有与主表student匹配。
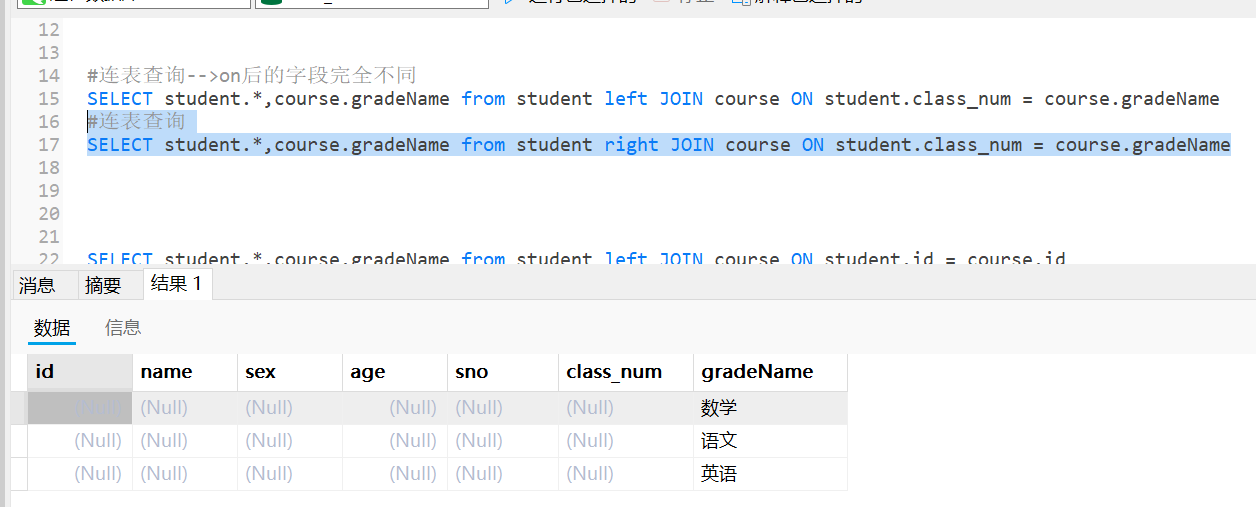
左连接后,以student为主表,查询出gradeName,一个都没有与主表course匹配。
结果总结:
以主表为主,如果任何字段都不相同,只显示主表。
二、主键
如果id为主键,以id为on后的条件,可以实现两表合并。
on后的条件决定了表结果的长度
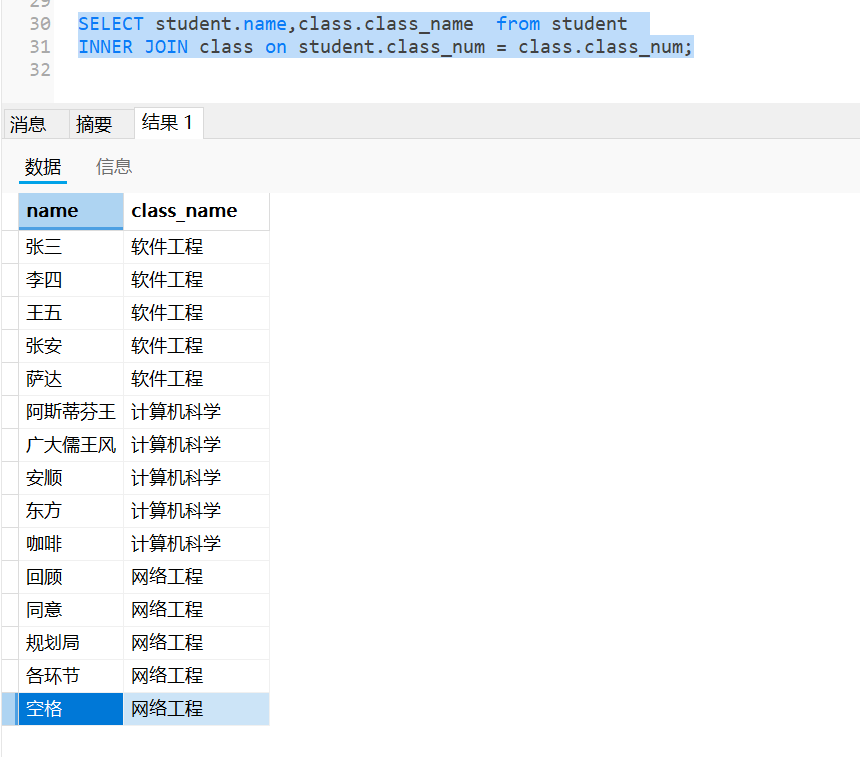
2.内连接 join或inner join
inner join是以两个表的交集,class_num有交集的就查的到
我们想要查询每个学生的班级名称,结果只包括那些实际有班级的学生。
举例:
学生表(student)
| sno | name | class_num |
|---|---|---|
| S001 | Alice | C001 |
| S002 | Bob | C002 |
| S003 | Charlie | C001 |
| S004 | David | C003 |
| S005 | Eva | NULL |
班级表(class)
| class_num | class_name |
|---|---|
| C001 | 一班 |
| C002 | 二班 |
| C003 | 三班 |
| C004 | 四班 |
SELECT student.sno, student.name, class.class_name
FROM student
INNER JOIN class ON student.class_num = class.class_num;
| sno | name | class_name |
|---|---|---|
| S001 | Alice | 一班 |
| S002 | Bob | 二班 |
| S003 | Charlie | 一班 |
| S004 | David | 三班 |
二、插入语句–insert
在设计表的时候id表要设置自动递增


id为自动递增的时候,不用设置递增。
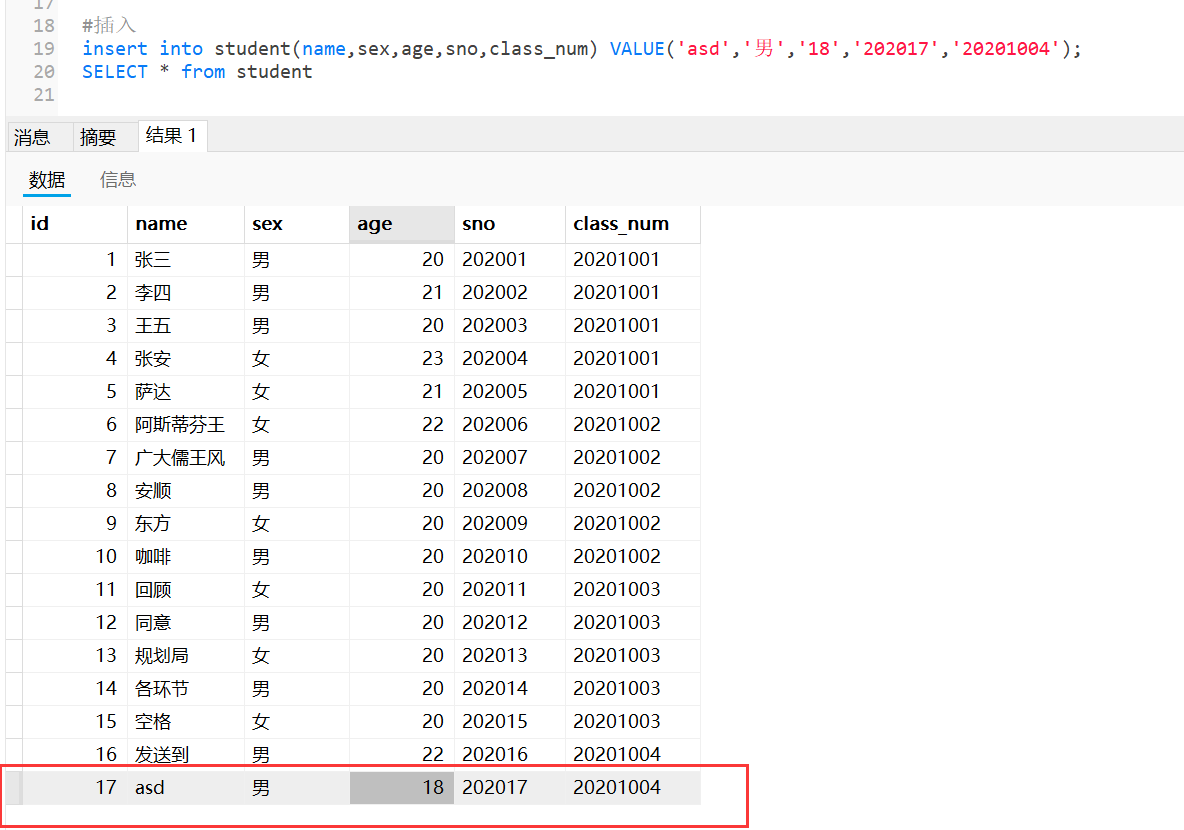
#插入
insert into student(name,sex,age,sno,class_num) VALUE('asd','男','18','202017','20201004');
SELECT * from student
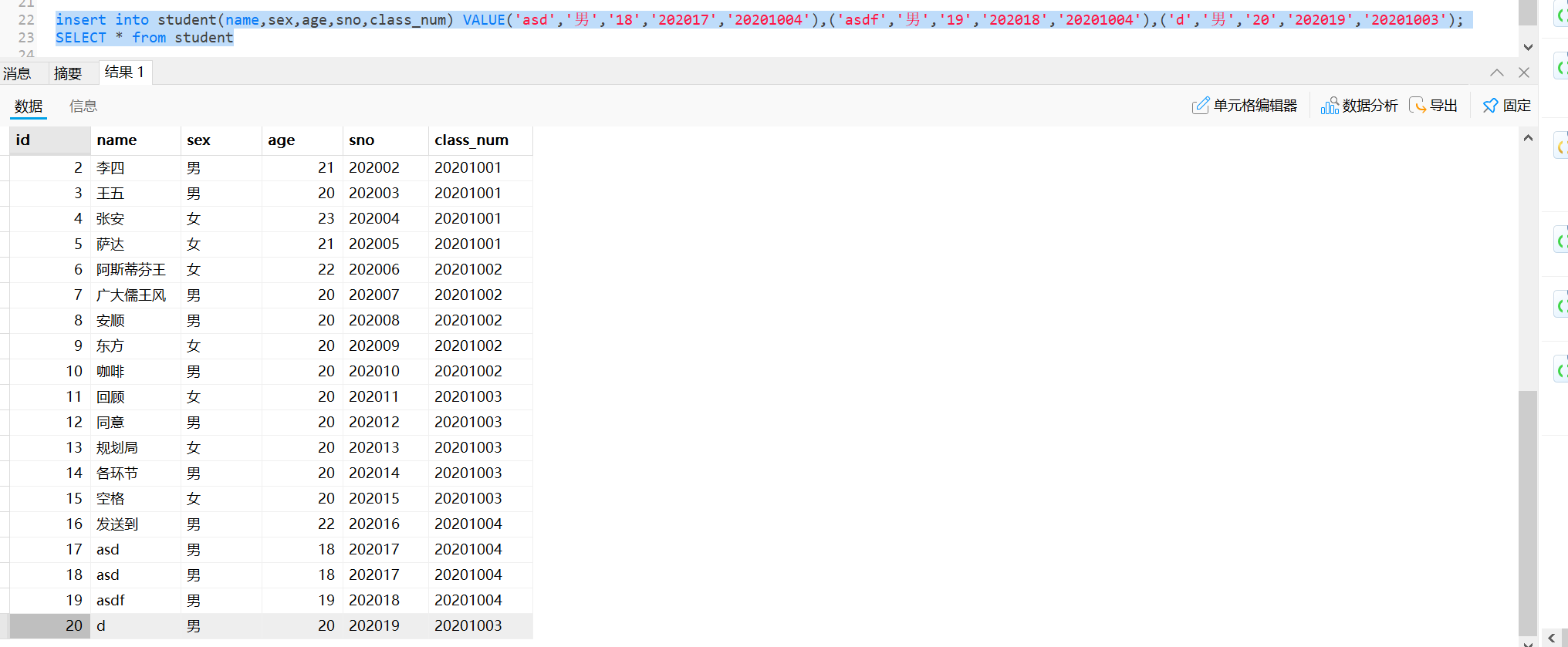
#插入多行
insert into student(列表1,列表2,列表3) VLAUE(值1,值2,值3),(值1,值2,值3),(值1,值2,值3),(值1,值2,值3);

一次插入多条数据
insert into student(name,sex,age,sno,class_num) VALUE('asd','男','18','202017','20201004'),('asdf','男','19','202018','20201004'),('d','男','20','202019','20201003');
SELECT * from student
四、update修改操作
一定要记得要添加上条件列,一般是id
# update 表名 set 列名
update student set name = "张三安",age = 20,sno='123456' where id =1
update student set name = "张三安",age = 20,sno='123456'
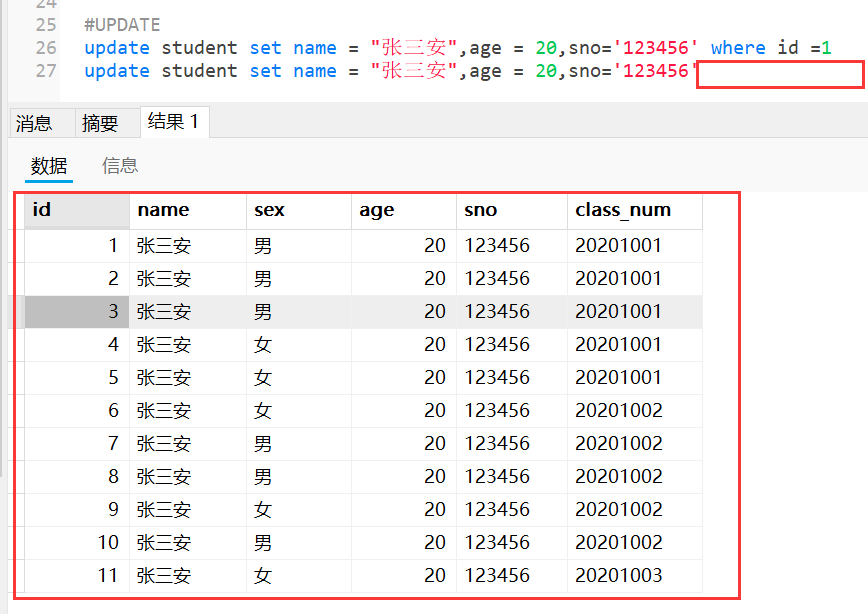
如果不加id,那么整个表对应的字段都被修改。
五、删除delete操作
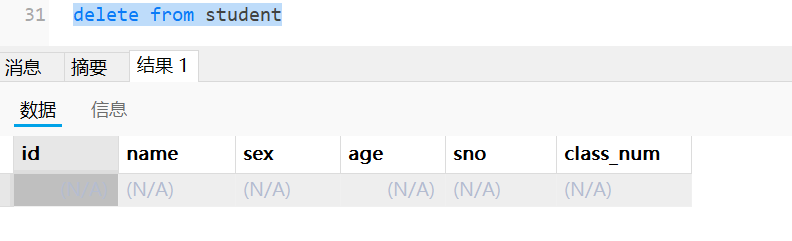
- delete from student 会逐行删除记录,并且每一行的删除都会被记录在事务日志中。
delete from 表名 where id = 1 # 一行行删除
delete from student #会删除 student 表中的每一条记录,但不会删除表结构本身。本质是一行行删除。
删除所有行:该语句会删除 student 表中的每一条记录,但不会删除表结构本身。
保留表结构:表的定义、列、约束(如主键、外键)以及索引等都会保留不变。

TRUNCATE 快速删除
TRUNCATE table 表名
# TRUNCATE table 表名 删除这张表,但是还是会创建一个和原始表结构一样的新表。相当于只删除表中的数据,保留表结构。
TRUNCATE TABLE student;
区别:
- 性能:
TRUNCATE通常比DELETE更快,因为它不逐行删除,而是直接释放数据页。
- 日志记录:
DELETE会为每一行删除操作记录日志,占用更多的事务日志空间。TRUNCATE记录的是页级别的操作,日志占用较少。
- 触发器:
DELETE会触发与删除操作相关的触发器(DELETE触发器)。TRUNCATE通常不会触发DELETE触发器,因为它不是逐行删除。
- 条件删除:
DELETE可以使用WHERE子句指定条件删除部分记录。TRUNCATE无法使用WHERE子句,只能删除所有记录。
drop—>彻底删除这张表
DROP TABLE 会删除整个表,包括表结构、数据和相关的约束。