
什么是RAG
-
知识局限性:大模型的知识来源于训练数据,而这些数据主要来自于互联网上已经公开的资源,对于一些实时性的或者非公开的,由于大模型没有获取到相关数据,这部分知识也就无法被掌握。
-
数据安全性:为了使得大模型能够具备相应的知识,就需要将数据纳入到训练集进行训练。然而,对于企业来说,数据的安全性至关重要,任何形式的数据泄露都可能对企业构成致命的威胁。
-
大模型幻觉:由于大模型是基于概率统计进行构建的,其输出本质上是一系列数值运算。因此,有时会出现模型“一本正经地胡说八道”的情况,尤其是在大模型不具备的知识或不擅长的场景中。
检索增强生成(Retrieval Augmented Generation, RAG),引入外部知识,使大模型能够生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。
1概览:一个完整的RAG链路
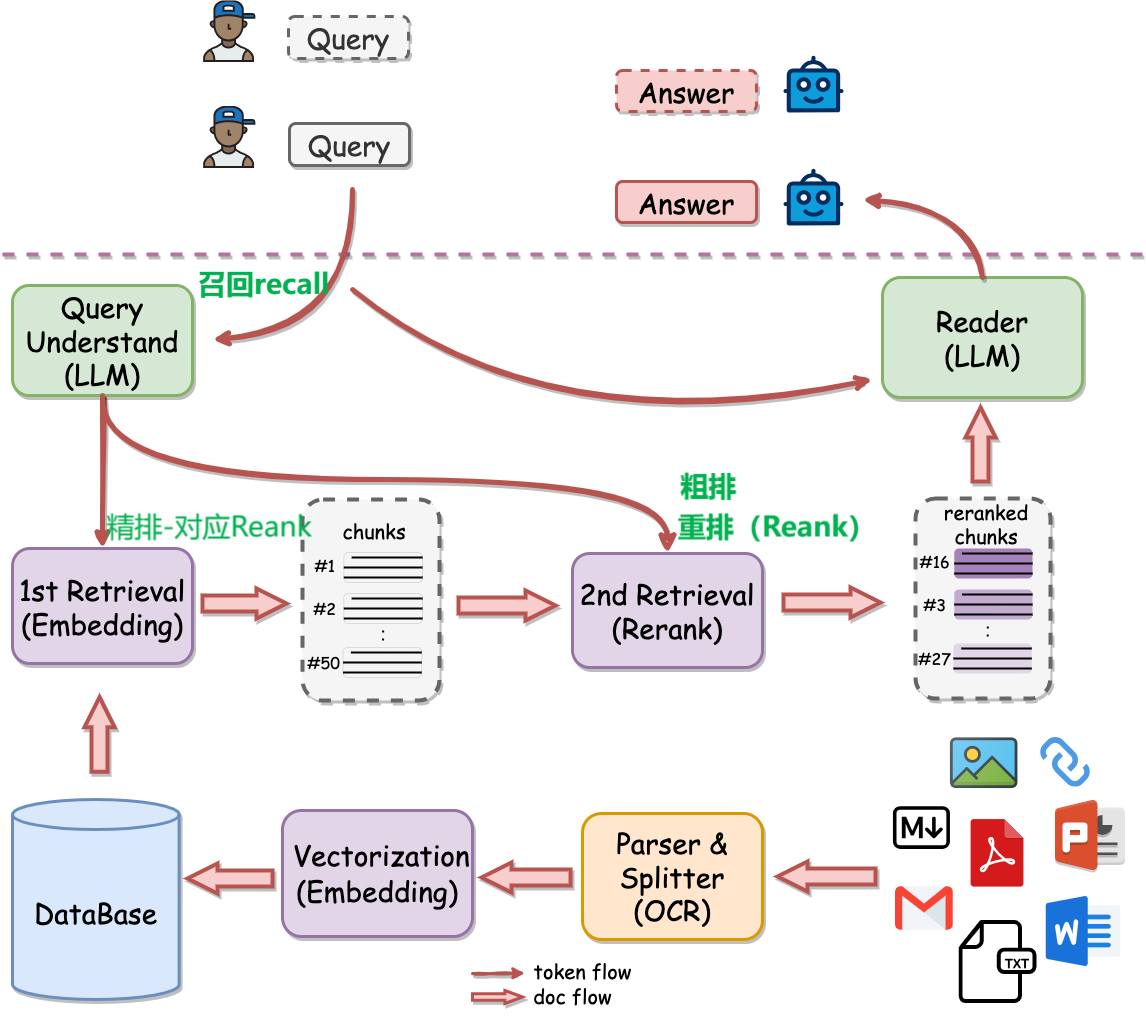
从上图可以看到,大模型接收到用户query后,RAG会先进行检索。
检索(Retrieval):检索 Chunks 和 query 一并输入到大模型,进而回答用户的问题。
Chunks:query和离线文档经过parser和splitter(orc)向量化(或称索引)——>到Datebase然后和query一起进行Retrieval——>检索到相关的Chunks
第二次Retrieval——>输入query和相关的Chunks然后得到reanked的Chunks输入到LLM后得到Answer
query:在第一次Retrieval和第二次Retrieval的时候输入
为了完成检索,需要离线将文档(ppt、word、pdf等)经过解析、切割甚至OCR转写,然后进行向量化存入数据库中。 接下来,我们将分别介绍离线计算和在线计算流程。
1.1离线计算流程
文件(pdf、word、ppt等,这些 文档documents)——解析parser——>切割为较短的Chunk——清洗和去重。
- 知识库中知识的数量和质量决定了RAG的效果,因此这是非常关键且必不可少的环节。
向量化(Vectorization):Chunk转化为向量或者 索引(Indexing)。
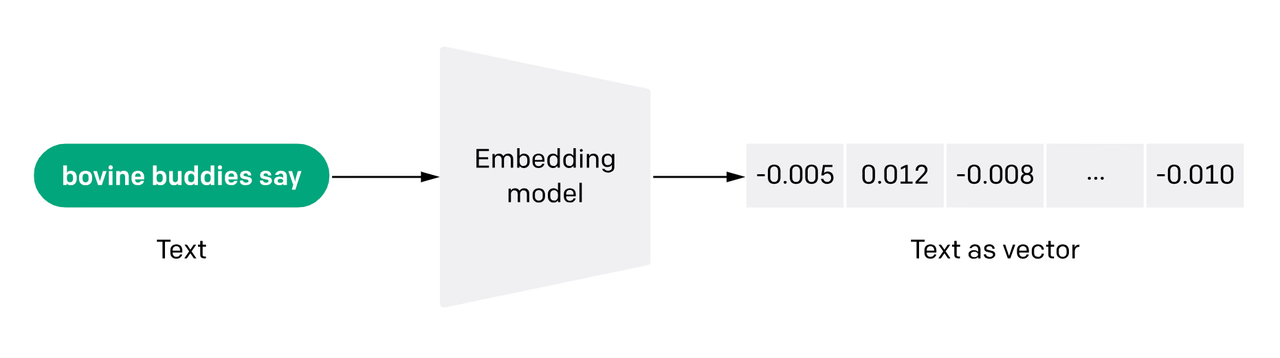
具体是构建**向量模型(Embedding Model)**作用是将一段 Chunk 转成 向量(Embedding)
- 一个好的向量模型,会使得具有相同语义的文本的向量表示在语义空间中的距离会比较近,而语义不同的文本在语义空间中的距离会比较远。
由于知识库中的所有 Chunk 都需要进行 向量化,这会使得计算量非常大,因此这一过程通常是离线完成的。
随着新知识的不断存储,向量的数量也会不断增加。这就需要将这些向量存储到 数据库 (DataBase)中进行管理,例如 Milvus 中。
离线计算总结:
离线计算就是在文档在parse&splitter后将得到的Chunk进行向量化(Vectorization)或称 索引(Indexing),随着向量的数量不断增加会将向量存储到Milvus等数据库中。
因为Chunk进行向量化的时候会使得计算量非常大,通常是离线进行的。
1.2在线计算
**检索(Retrieval):**RAG系统使用时候,给定一条用户 查询(Query),从知识库中找到所需的知识的操作。
具体过程:Query会经过向量模型(Embedding Model)【是的也就是向量化】得到相应向量,然后与数据库中所有的Chunk的向量计算相似度*,得到最相近的一系列Chunk。
但 数据库 非常大的时候,向量相似度的计算过程需要一定的时间。
这时可以在索引之前那召回(Recall):从 数据库 中快速获得大量大概率相关的 Chunk,**然后只有这些 Chunk 会参与计算向量相似度。**使得计算的复杂度就从整个知识库降到了非常低。
召回(Recall):
召回(Recall):通常采用简单的基于字符串的匹配算法,常用的算法有 TF-IDF,BM25 。【由于这些算法不需要任何模型,速度会非常快】
**总结:**在查询(Query)前增加了召回(recall),即从数据库中快速获得大量大概率相关的Chunk,用这些大概率相关的Chunk进行计算向量相似度。达到降低计算复杂度的效果。
思维导图:向量化——query所有向量进行计算向量相似度,得到Chunk
而是在此之前增加recall进行大概率相关的Chunk计算向量相似度。
但人们发现,随着知识库的增大,除了检索的速度变慢外,检索的效果也会出现退化,如下图中绿线所示: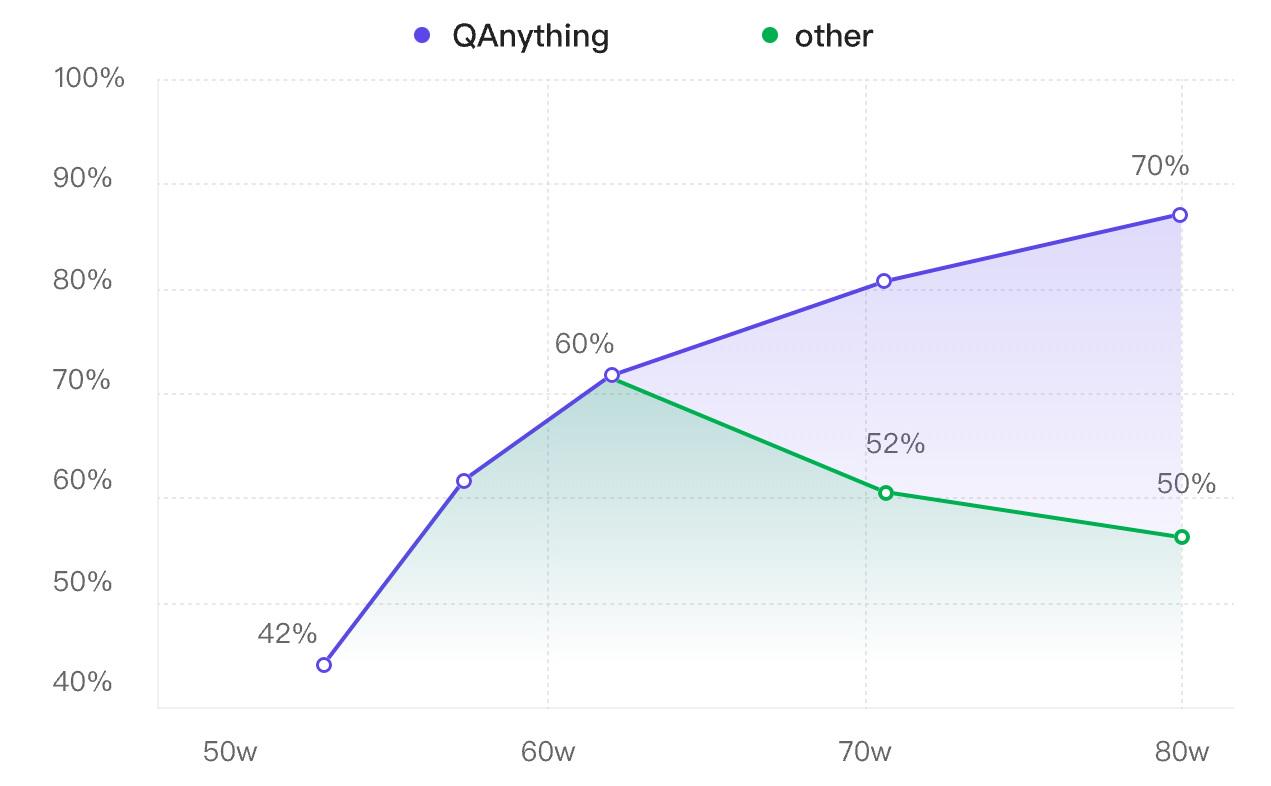
这是由于向量模型 (Embedding Model)能力有限。
知识库增大,超过了向量模型的容量,这种情况下相似度最高的结果可能不是最优的,因此准确度就下降了。
为解决随着知识库的增大,除了检索的速度变慢外,检索的效果也会出现退化的问题,
研究者提出增加一个二阶段检索——
重排 (Rerank):
即利用 重排模型(Reranker),使得越相似的结果排名更靠前。
这样就能实现准确率稳定增长,即数据越多,效果越好(如上图中紫线所示)。
一阶段检索有时也被称为 精排 。而在一些更复杂的系统中,在 召回 和 精排 之间还会添加一个 粗排 步骤。
综上所述,在整个 检索 过程中,计算量的顺序是 召回 > 精排 > 重排,而检索效果的顺序则是 召回 < 精排 < 重排 。
当这一复杂的 检索 过程完成后,我们就会得到排好序的一系列 检索文档(Retrieval Documents)。
然后我们会从其中挑选最相似的 k 个结果,将它们和用户查询拼接成prompt的形式,输入到大模型。
最后,大型模型就能够依据所提供的知识来生成回复,从而更有效地解答用户的问题。
在线计算总结:
一阶段检索(精排)(召回recall):在查询(Query)前增加了召回(recall),即从数据库中快速获得大量大概率相关的Chunk,用这些大概率相关的Chunk进行计算向量相似度。达到降低计算复杂度的效果。
复杂的系统中有时候会在召回recall与精排添加一个粗排的步骤
**二阶段检索(重排)(重排模型Reanker):**为解决随着知识库的增大,除了检索的速度变慢外,检索的效果也会出现退化的问题。【本质向量模型容量问题】。重排模型(Reanker)使得越相似的结果排名更靠前,实现准确率稳定增长,即数据越多,效果越好。
最终得到的是排好序的一系列 检索文档(Retrieval Documents)。
检索(Retrieval)就是以上的一个过程。
2开源RAG框架**
目前,开源社区中已经涌现出了众多RAG框架,例如:
- TinyRAG:DataWhale成员宋志学精心打造的纯手工搭建RAG框架。
- LlamaIndex:一个用于构建大语言模型应用程序的数据框架,包括数据摄取、数据索引和查询引擎等功能。
- LangChain:一个专为开发大语言模型应用程序而设计的框架,提供了构建所需的模块和工具。
- QAnything:网易有道开发的本地知识库问答系统,支持任意格式文件或数据库。
- RAGFlow:InfiniFlow开发的基于深度文档理解的RAG引擎。
- ···
再理解RAG的链路图:
1.离线计算就是说的图片下方,文档经过patser&Splitter后得到Chunk然后进行向量化Vectorization,然后再存储到DataBase中。
- 向量化就是利用向量模型Embedding Model将Chunk转化为向量,得到各个文本在语义空间的相似度。
2.在线计算就是图片上方,用户的查询Query经过大模型理解,经过1st检索(Retrival)及经过2st 检索(Retrival)最终得到检索文档(Retrieval Documents)与查询Query拼接成prompt的形式,输入到大模型中,大模型根据所提供的知识回答问题。
具体来说:1st Retrival中为了解决Query向量化后 与 向量数据库中所有的Chunk的计算向量相似度的问题,提出在Query进大模型之前进行召回recall,降低了计算复杂度。_有些会在召回和精排(1st Retrival)之间增加粗排。
召回(Recall):从数据库中快速获得大量大概率相关的Chunk**,**然后只有这些Chunk会参与计算向量相似度。**使得计算的复杂度就从整个知识库降到了非常低。_也有直接更快速搜索的方案faiss,annoy。
但知识库的增大,除了检索的速度变慢外,检索的效果也会出现退化,为解决这个问题:_本质是向量模型容量问题
提出2st Retrival中增加重排(Reank),使得向量相似度越相似的结果排名更靠前,实现准确率稳定增长。