
Datawhale AI夏令营第四期大模型应用开发-Task01
首先了解一些背景知识。
一、什么是大模型
语言模型发展历史
-
语言模型:为了对人类语言的内在规律进行建模,研究者们提出使用语言模型(language model)来准确预测词序列中
下一个词或者缺失的词的概率。 -
统计语言模型:使用马儿可夫假设,假设当前词与之前的词产生联系。
中文中,建立n元语言模型,n元作为最小的语义单元进行建模
-
神经语言模型
- 上下文
-
统计语言模型(Statistical Language Model, SLM):使用马尔可夫假设(Markov Assumption)来建模语言序列的 𝑛 元(𝑛-gram)语言模型
-
神经语言模型(Neural Language Model, NLM):基于神经网络构建语言模型,如循环神经网络(Recurrent Neural Networks, RNN),并学习上下文相关的词表示(即分布式词向量),也被称为词嵌入(Word Embedding)。代表性工作:word2vec
-
预训练语言模型(Pre-trained Language Model, PLM):使用大量的无标注数据预训练双向 LSTM(Bidirectional LSTM, biLSTM)或者Transformer,然后在下游任务上进行微调(Fine-Tuning)。代表性工作:ELMo、BERT、GPT-1/2
- 双向lstm是在RNN基础上进行改进的模型
- Transformer,使用多层自注意力结构的模型
- 无标注数据:数据没有任何人标注,数据自监督的方式进行学习-
- 形成了预训练微调的范式
-
大语言模型(Large Language Model, LLM):基于“扩展法则”(Scaling Law),即通过增加模型参数或训练数据,可以提升下游任务的性能,同时具有小模型不具有的“涌现能力”(Emergent Abilities)。代表性工作:GPT-3、ChatGPT、Claude、Llama

二、大模型是怎么构建的(三个阶段)
大模型的构建过程可以分为预训练(Pretraining)、有监督微调(Supervised Fine-tuning, SFT)、基于人类反馈的强化学习对齐(Reinforcement Learning from Human Feedback, RLHF)三个阶段。
1.预训练(Pretraining)
- 使用海量的数据进行模型参数的初始学习,旨在为模型参数寻找到一个优质的“起点”。
(1)预训练技术的发展
这一概念最初在计算机视觉领域萌芽,通过在ImageNet(一个大型图像数据集)上的训练,为模型参数奠定了坚实的基础。
后来在自然语言处理(NLP)领域使用,word2vec开创先河,利用未标注文本构建词嵌入模型;ELMo、BERT及GPT-1则进一步推动了**“预训练-微调”范式**的普及。
起初,只用于解决特定类别的下游任务;例如文本分类、序列标注、序列到序列生成等传统NLP任务。
之后,GPT-2——通过大规模文本数据预训练:打造能够应对广泛任务的通用解决方案,并在GPT-3中将这一理念扩展至前所未有的超大规模。
- 在BERT等早期预训练模型中,模型架构和训练任务呈现出多样化特征。然而,随着GPT系列模型的兴起,“解码器架构+预测下一个词”的策略证明了其卓越效能,成为了当前主流的大模型技术路线。
(2)预训练的过程
搜集和清洗文本数据
首要任务是搜集和清洗海量的文本数据,确保剔除潜在的有害内容。获取高质、多元的数据集,并对其进行严谨的预处理。
鉴于模型的知识库几乎完全源自训练数据,数据的质量与多样性对模型性能至关重要。这是打造高性能语言模型的关键步骤。
当前,多数开源模型的预训练均基于数T的token。
| 大模型 | token | 计算资源需求 |
|---|---|---|
| Llama-1 | 1T | 2,048块A100 80GB GPU三周 |
| Llama-2 | 2T | |
| Llama-3 | 15T |
除了对数据量的苛刻要求,预训练阶段对计算资源的需求也极为庞大。以Llama-1的65B参数模型为例,其在2,048块A100 80GB GPU集群上进行了接近三周的训练。
训练及细节
- 此外,预训练过程中还涉及诸多细节,诸如数据配比、学习率调度、模型行为监测等,这些往往缺乏公开的最佳实践指导,需要研发团队具备深厚的训练经验与故障排查能力,以规避训练过程中的回溯与重复迭代,节约计算资源,提高训练效率。
总体而言,预训练不仅是一项技术挑战,更是一场对数据质量、算力投入与研发智慧的综合考验。
2.有监督微调(Supervised Fine-tuning, SFT)或**指令微调(instruction tuning)
预训练模型能力限制
-
大规模预训练后,模型已经具备较强的模型能力,能够编码丰富的世界知识,但是由于预训练任务形式所限,
-
这些模型更擅长于文本补全,并不适合直接解决具体的任务。
尽管引入了诸如上下文学习(In-Context Learning, ICL)等提示学习策略以增强模型的适应性,但模型本身在下游任务解决上的能力仍受限。为了克服这一局限,预训练后的大型语言模型往往需经历微调过程,以提升其在特定任务中的表现。
目前来说,比较广泛使用的微调技术是“有监督微调”(也叫做指令微调,Instruction Tuning):该方法利用成对的任务输入与预期输出数据,训练模型学会以问答的形式解答问题,从而解锁其任务解决潜能。
经过指令微调后,大语言模型能够展现出较强的指令遵循能力,可以通过零样本学习的方式解决多种下游任务。
指令微调更多地扮演着催化剂的角色,激活模型内在的潜在能力,而非单纯地灌输信息。**
SFT的优点
相较于预训练所需的海量数据,指令微调所需数据量显著减少,从几十万到上百万条不等的数据,均可有效激发模型的通用任务解决能力,甚至有研究表明,少量高质量的指令数据(数千至数万条)亦能实现令人满意的微调效果。这不仅降低了对计算资源的依赖,也提升了微调的灵活性与效率。
3.基于人类反馈的强化学习对齐
除了提升任务的解决能力外,大语言模型与**人类期望、需求及价值观的对齐(Alignment)**至关重要,这对于大模型的应用具有重要的意义。
InstructGPT论文提出
InstructGPT论文解读 - 知乎 (zhihu.com)OpenAI在 2022 年初发布
详尽阐述了如何实现语言模型与人类对齐。论文提出了基于人类反馈的强化学习对齐(Reinforcement Learning from Human Feedback, RLHF),通过指令微调后的强化学习,提升模型的人类对齐度。RLHF的核心在于构建一个反映人类价值观的奖励模型(Reward Model)。这一模型的训练依赖于专家对模型多种输出的偏好排序,通过偏好数据训练出的奖励模型能够有效评判模型输出的质量。
其他简化方法
目前还有很多工作试图去除复杂的强化学习算法,或其他使用 SFT 方式来达到与 RLHF 相似的效果,从而简化模型的对齐过程。
- 直接偏好优化(Direct Preference Optimization, DPO),它通过与有监督微调相似的复杂度实现模型与人类对齐,是一种典型的不需要强化学习的对齐算法。相比RLHF,DPO不再需要在训练过程中针对大模型进行采样,同时超参数的选择更加容易。
最后,我们以开源大模型Llama-2-Chat为例,简要介绍一下其训练过程。
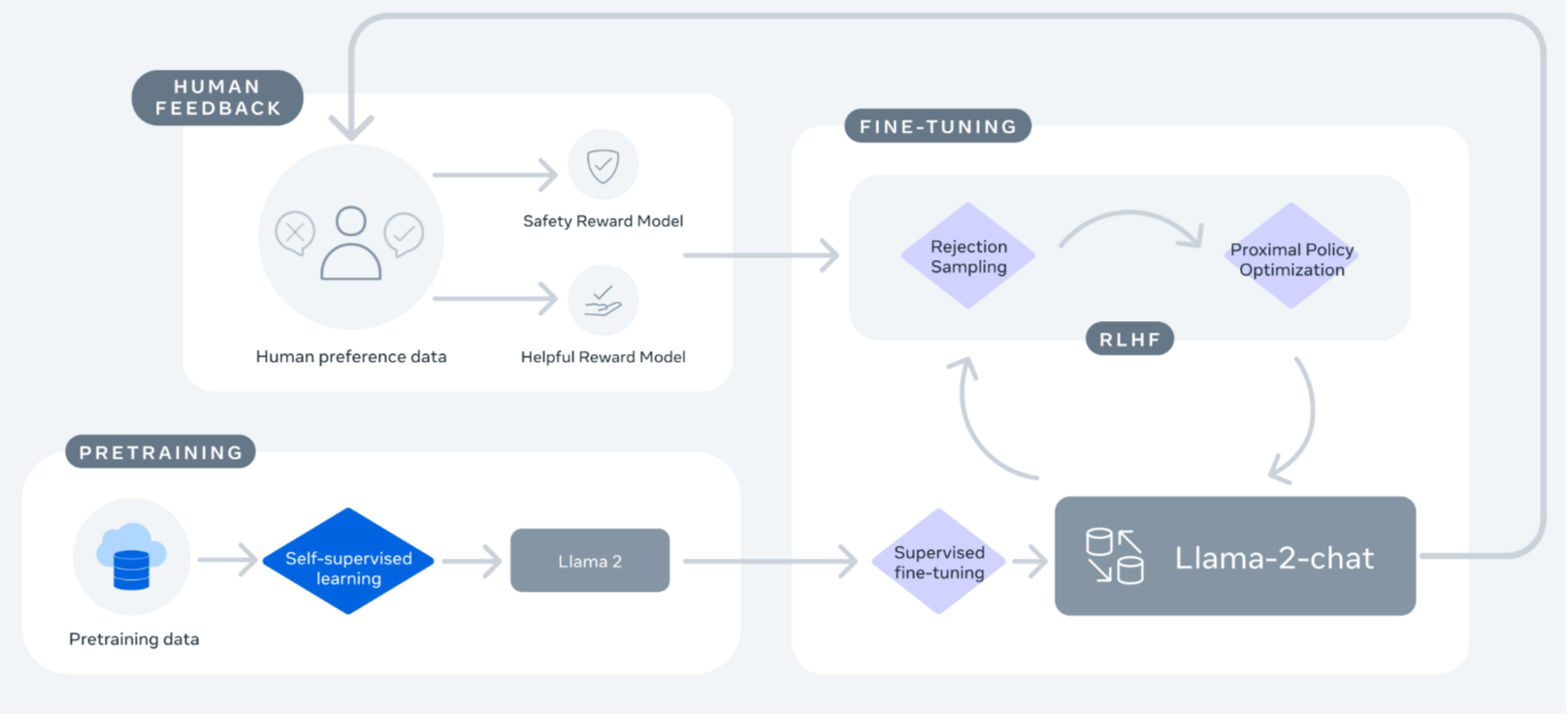
整个过程起始于利用公开数据进行预训练,获得Llama-2。在此之后,通过有监督微调创建了Llama-2-Chat的初始版本。随后,使用基于人类反馈的强化学习(RLHF)方法来迭代地改进模型,具体包括拒绝采样(Rejection Sampling)和近端策略优化(Proximal Policy Optimization, PPO)。在RLHF阶段,人类偏好数据也在并行迭代,以保持奖励模型的更新。
三、开源大模型和闭源大模型
根据上面的学习,我们不难发现,构建大模型不仅需要海量的数据,更依赖于强大的计算能力,以确保模型能够快速迭代和优化,从而达到预期的性能水平。鉴于此,全球范围内能够独立承担起如此庞大计算成本的机构屈指可数。这些机构可以分为以下两大阵营:
-
一是选择将模型开源的组织,他们秉持着促进学术交流和技术创新的理念,让全球的研究者和开发者都能受益于这些模型。通过开放模型的代码和数据集,他们加速了整个AI社区的发展,促进了创新和技术的民主化。这一阵营的代表有Meta AI、浪潮信息等。
-
另一类则是保持模型闭源的公司,它们通常将模型作为核心竞争力,用于提供专有服务或产品,以维持商业优势。闭源模型通常伴随着专有技术和服务,企业可以通过API等方式提供给客户使用,而不直接公开模型的细节或代码。这种模式有助于保障公司的商业利益,同时也为用户提供了稳定和安全的服务。这一阵营的代表有OpenAI、百度等。
无论是开源还是闭源,这些大模型都在推动人工智能领域向前发展,对于推动大语言模型技术的渐进式发展起到了至关重要的作用。
接下来,我们以浪潮信息为例,简要介绍下浪潮信息源大模型开源体系。
四、源大模型开源体系(浪潮信息)
截止到目前,浪潮信息已经发布了三个大模型:源1.0 ,源2.0 和 源2.0-M32,其中 源1.0 开放了模型API、高质量中文数据集和代码,源2.0 和 源2.0-M32 采用全面开源策略,全系列模型参数和代码均可免费下载使用。

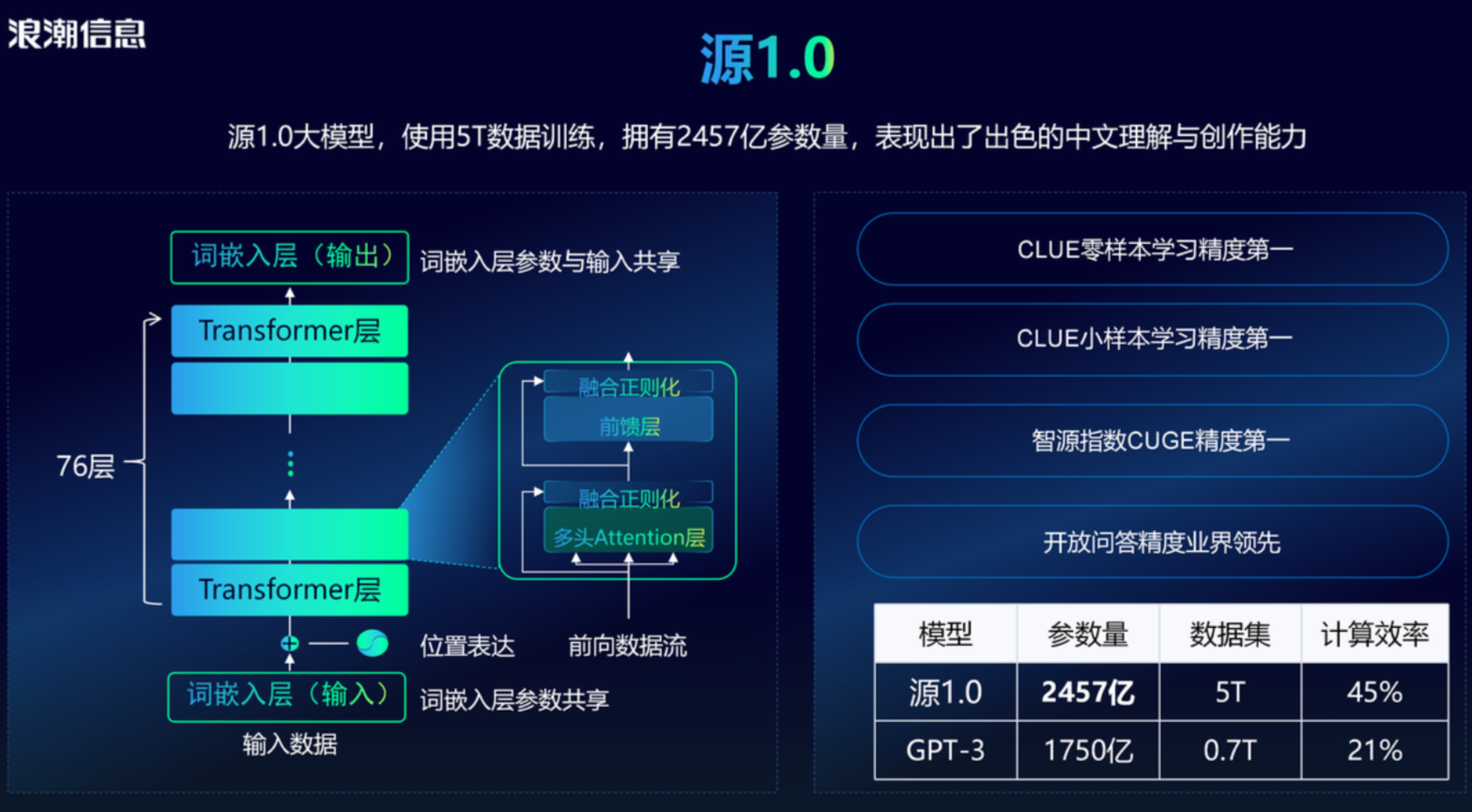
2021年9月,源1.0大模型发布,它采用76层的Transformer Decoder结构,使用5T数据训练,拥有2457亿参数量,超越OpenAI研发的GPT-3,成为全球最大规模的AI巨量模型,表现出了出色的中文理解与创作能力。
- 项目链接: https://github.com/Shawn-IEITSystems/Yuan-1.0
- 官方报道: https://mp.weixin.qq.com/s/6CH0I4eOLzj3YDZyIxdeEQ
- 论文链接: https://arxiv.org/abs/2110.04725
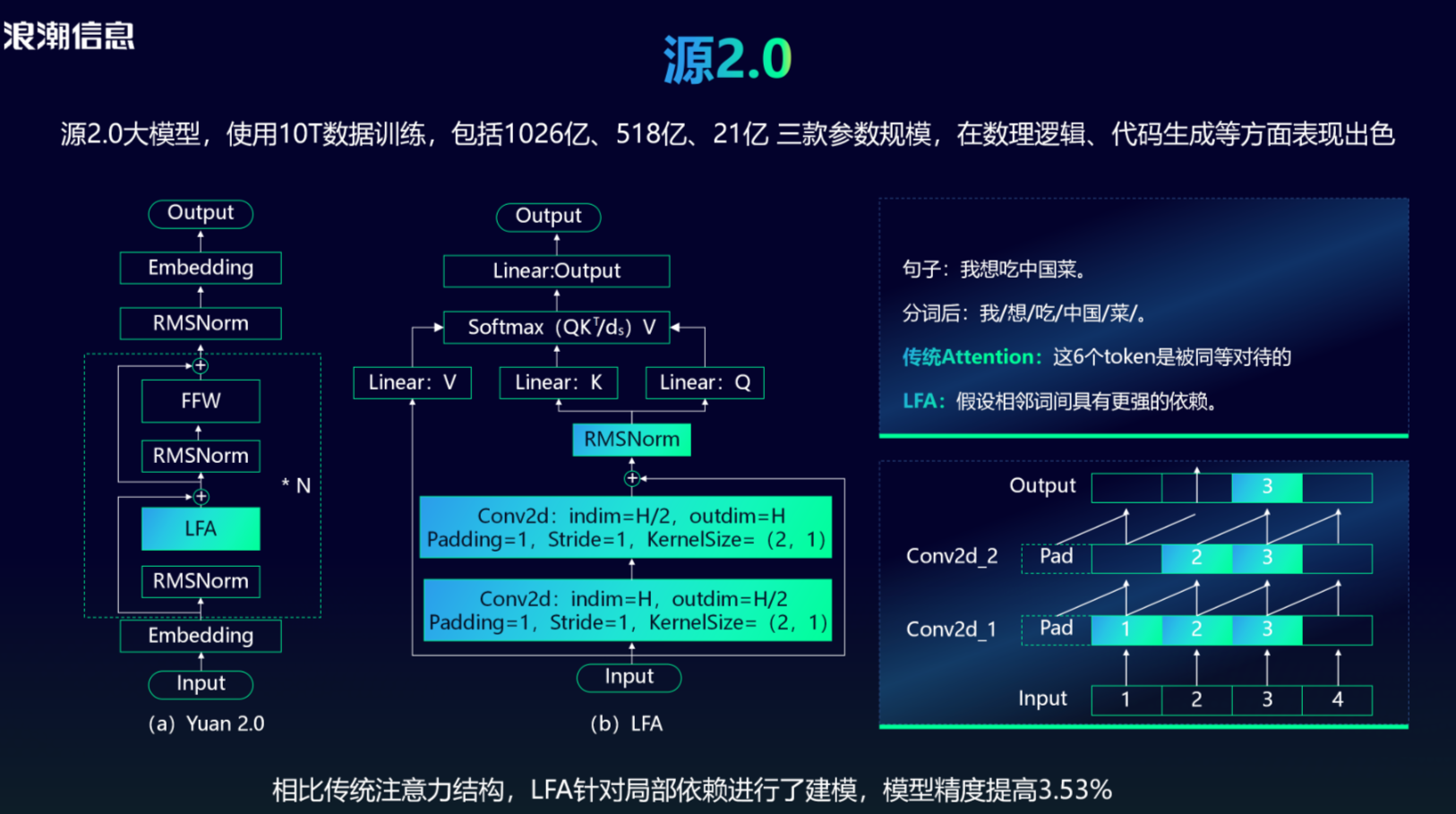
2023年11月,源2.0大模型发布,它使用10T数据训练,包括1026亿、518亿、21亿 三款参数规模,在数理逻辑、代码生成等方面表现出色。
在算法方面,与传统Attention对输入的所有文字一视同仁不同,
局部注意力过滤增强机制(Localized Filtering-based Attention, LFA)
源2.0提出,它假设自然语言相邻词之间有更强的语义关联,因此针对局部依赖进行了建模,最后使得模型精度提高3.53%。
- 项目链接: https://github.com/IEIT-Yuan/Yuan-2.0
- 官方报道: https://mp.weixin.qq.com/s/rjnsUS83TT7aEN3r2i0IPQ
- 论文链接: https://arxiv.org/abs/2311.15786
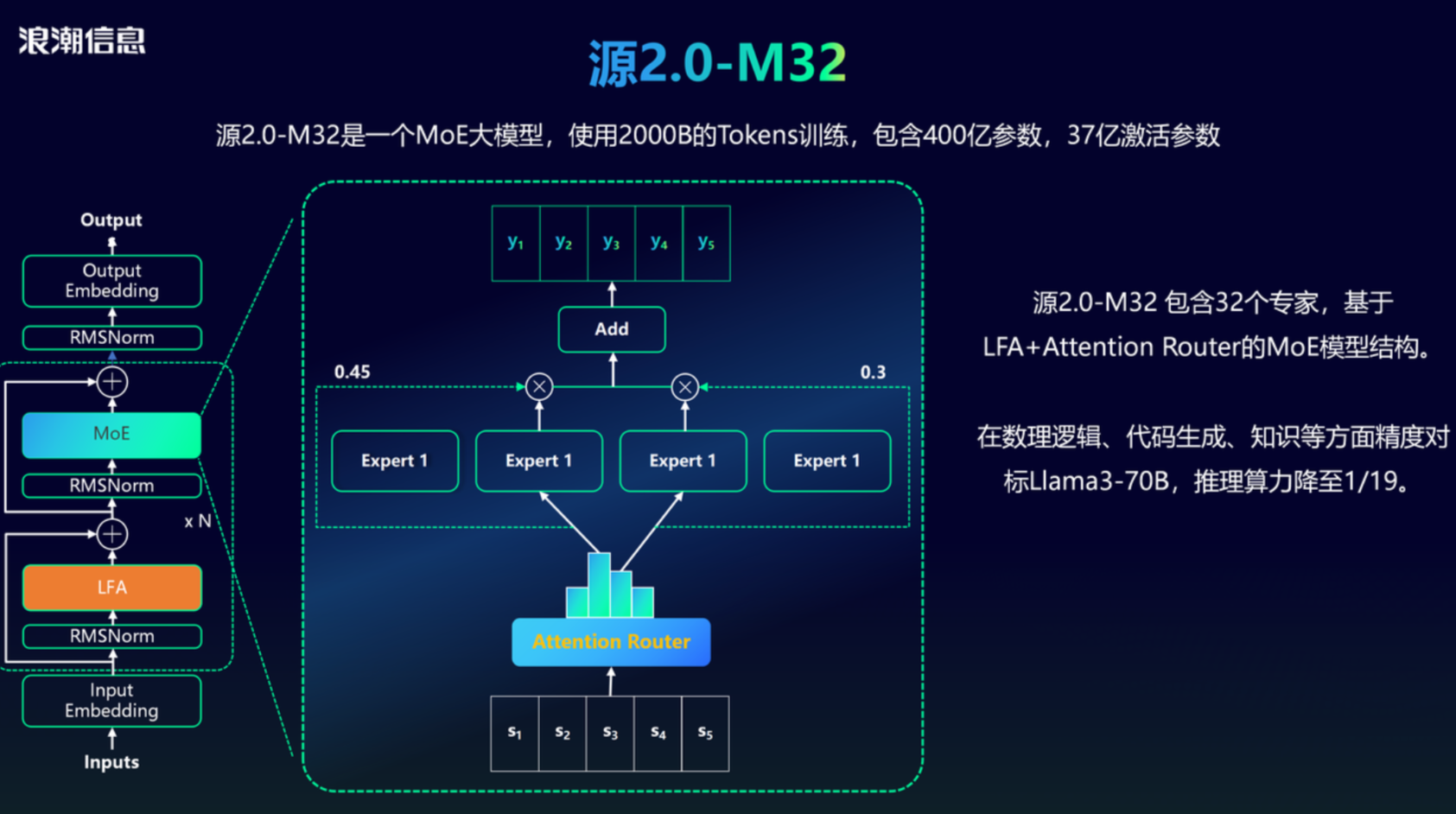
2024年5月,源2.0-M32发布,它是一个混合专家(Mixture of Experts, MoE)大模型,使用2000B Tokens训练,包含400亿参数,37亿激活参数
源2.0-M32 包含32个专家,基于LFA+Attention Router的MoE模型结构。
源2.0-M32 在数理逻辑、代码生成、知识等方面精度对标Llama3-70B,推理算力降至1/19。
- 项目链接: https://github.com/IEIT-Yuan/Yuan2.0-M32
- 官方报道: https://mp.weixin.qq.com/s/WEVyYq9BkTTlO6EAfiCf6w
- 论文链接: https://arxiv.org/abs/2405.17976
本次学习,我们将以 源2.0-2B 模型为例,带领大家一起体验源大模型,欢迎大家来给项目点点 star 哦!
五、大模型时代挖掘模型能力的开发范式
进入大模型时代,人工智能领域的边界正以前所未有的速度扩展,而如何充分挖掘大模型的内在潜能,成为了应用开发者面前的一道关键课题。
在这一背景下,不同的应用场景催生了多样化的应用开发策略,这些策略不仅展现了大模型应用开发的丰富可能性,也预示着未来AI技术在各行业落地的广阔前景。
有手就行的Prompt工程
Prompt工程(Prompt Engineering)是指通过精心构造提示(Prompt),直接调教大模型,解决实际问题。
为了更充分地挖掘大模型的潜能,出现了以下两种技术:
LCT和CoT
- 上下文学习(In-Context Learning, ICL):将任务说明及示例融入提示文本之中,利用模型自身的归纳能力,无需额外训练即可完成新任务的学习。
- 思维链提示(Chain-of-Thought, CoT):引入连贯的逻辑推理链条至提示信息内,显著增强了模型处理复杂问题时的解析深度与广度。
Embedding辅助给LLM外接大脑
尽管大模型具有非常出色的能力,然而在实际应用场景中,仍然会出现大模型无法满足我们需求的情况,主要有以下几方面原因:
- 知识局限性:大模型的知识来源于训练数据,而这些数据主要来自于互联网上已经公开的资源,对于一些实时性的或者非公开的,由于大模型没有获取到相关数据,这部分知识也就无法被掌握。
- 数据安全性:为了使得大模型能够具备相应的知识,就需要将数据纳入到训练集进行训练。然而,对于企业来说,数据的安全性至关重要,任何形式的数据泄露都可能对企业构成致命的威胁。
- 大模型幻觉:由于大模型是基于概率统计进行构建的,其输出本质上是一系列数值运算。因此,有时会出现模型“一本正经地胡说八道”的情况,尤其是在大模型不具备的知识或不擅长的场景中。
因此,将知识提前转成Embedding向量,存入知识库,然后通过检索将知识作为背景信息,这样就相当于给LLM外接大脑,使大模型能够运用这些外部知识,生成准确且符合上下文的答案,同时能够减少模型幻觉的出现。
参数高效微调Parameter-efficient Fine-tuning,轻量化微调Lightweight Fine-tuning
在实际应用场景中,大模型还会经常出现以下问题:
- 大模型在当前任务上能力不佳,如果提升其能力?
- 另外,怎么使大模型学习其本身不具备的能力呢?
这些问题的答案是模型微调。
模型微调也被称为指令微调(Instruction Tuning)或者有监督微调(Supervised Fine-tuning, SFT),首先需要构建指令训练数据,然后通过有监督的方式对大模型的参数进行微调。经过模型微调后,大模型能够更好地遵循和执行人类指令,进而完成下游任务。
然而,由于大模型的参数量巨大, 进行全量参数微调需要消耗非常多的算力。为了解决这一问题,研究者提出了参数高效微调(Parameter-efficient Fine-tuning),也称为轻量化微调 (Lightweight Fine-tuning),这些方法通过训练极少的模型参数,同时保证微调后的模型表现可以与全量微调相媲美。
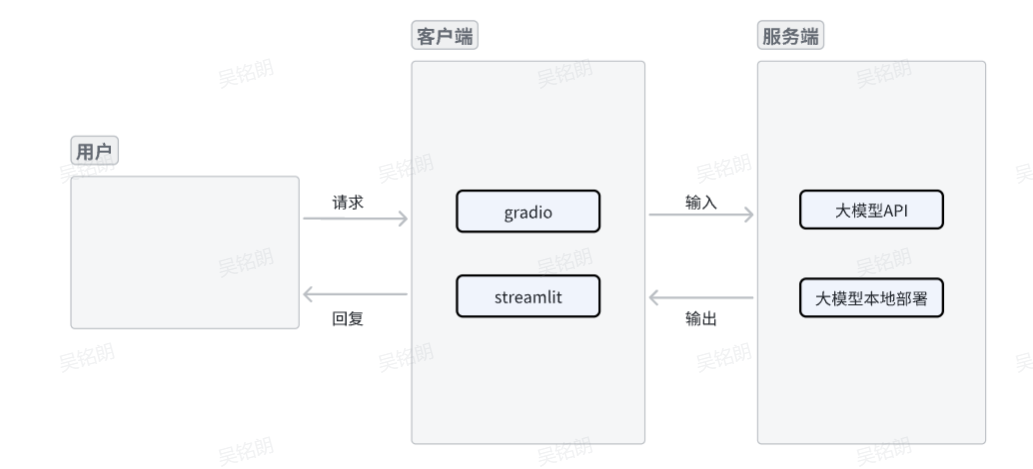
六、大模型应用开发 必知必会
通常,一个完整的大模型应用包含一个客户端和一个服务端。
客户端接收到用户请求后,将请求输入到服务端,服务端经过计算得到输出后,返回给客户端回复用户的请求。
客户端
在大模型应用中,客户端需要接受用户请求,并且能将回复返回给用户。
目前,客户端通常使用 Gradio 和 Streamlit 进行开发。
Gradio 基本概念
https://datawhaler.feishu.cn/sync/C8BfdAPevsOWctbpowocZYOGnmb
Streamlit 基础概念
https://datawhaler.feishu.cn/sync/AylRdptJis6baEbW2f9cW17snVh
服务端
在大模型应用中,服务端需要与大模型进行交互,大模型接受到用户请求后,经过复杂的计算,得到模型输出。
目前,服务端主要有以下两种方式:
直接调用大模型API
-
直接调用大模型API:将请求直接发送给相应的服务商,如openai,讯飞星火等,等待API返回大模型回复
-
✔️ 优点:
-
- 便捷性: 不需要关心模型的维护和更新,服务商通常会负责这些工作。
- 资源效率: 避免了本地硬件投资和维护成本,按需付费,灵活调整成本支出。
- 稳定性与安全性: 专业团队管理,可能提供更好的系统稳定性和数据安全性措施。
- 扩展性: API服务易于集成到现有的应用和服务中,支持高并发请求。
-
✖️ 缺点:
-
- 网络延迟: 需要稳定的网络连接,可能会受到网络延迟的影响。
- 数据隐私: 数据需要传输到服务商的服务器,可能涉及数据安全和隐私问题。
- 成本控制: 高频次或大量数据的调用可能会导致较高的费用。
- 依赖性: 受制于服务商的政策变化,如价格调整、服务条款变更等。
**大模型本地部署
-
大模型本地部署**:在本地GPU或者CPU上,下载模型文件,并基于推理框架进行部署大模型**
-
✔️ 优点:
-
- 数据主权: 数据完全在本地处理,对于敏感数据处理更为安全。
- 性能可控: 可以根据需求优化配置,减少网络延迟,提高响应速度。
- 成本固定: 初始投入后,长期运行成本相对固定,避免了按使用量付费的不确定性。
- 定制化: 更容易针对特定需求进行模型微调或扩展。
-
✖️ 缺点:
-
- 硬件投资: 需要强大的计算资源,如高性能GPU,初期投资成本较高。
- 运维复杂: 需要自行管理模型的更新、维护和故障排查。
- 技术门槛: 对于非专业团队而言,模型的部署和优化可能较为复杂。
- 资源利用率: 在低负载情况下,本地硬件资源可能无法充分利用。
-
综上,选择哪种方式取决于具体的应用场景、数据敏感性、预算以及对延迟和性能的需求。
来精读一下baseline
-
完整baseline代码
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 创建一个标题和一个副标题
st.title("💬 Yuan2.0 智能编程助手")
# 源大模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('IEITYuan/Yuan2-2B-Mars-hf', cache_dir='./')
# model_dir = snapshot_download('IEITYuan/Yuan2-2B-July-hf', cache_dir='./')
# 定义模型路径
path = './IEITYuan/Yuan2-2B-Mars-hf'
# path = './IEITYuan/Yuan2-2B-July-hf'
# 定义模型数据类型
torch_dtype = torch.bfloat16 # A10
# torch_dtype = torch.float16 # P100
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():
print("Creat tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(path, add_eos_token=False, add_bos_token=False, eos_token='<eod>')
tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)
print("Creat model...")
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch_dtype, trust_remote_code=True).cuda()
print("Done.")
return tokenizer, model
# 加载model和tokenizer
tokenizer, model = get_model()
# 初次运行时,session_state中没有"messages",需要创建一个空列表
if "messages" not in st.session_state:
st.session_state["messages"] = []
# 每次对话时,都需要遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:
st.chat_message(msg["role"]).write(msg["content"])
# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():
# 将用户的输入添加到session_state中的messages列表中
st.session_state.messages.append({"role": "user", "content": prompt})
# 在聊天界面上显示用户的输入
st.chat_message("user").write(prompt)
# 调用模型
prompt = "<n>".join(msg["content"] for msg in st.session_state.messages) + "<sep>" # 拼接对话历史
inputs = tokenizer(prompt, return_tensors="pt")["input_ids"].cuda()
outputs = model.generate(inputs, do_sample=False, max_length=1024) # 设置解码方式和最大生成长度
output = tokenizer.decode(outputs[0])
response = output.split("<sep>")[-1].replace("<eod>", '')
# 将模型的输出添加到session_state中的messages列表中
st.session_state.messages.append({"role": "assistant", "content": response})
# 在聊天界面上显示模型的输出
st.chat_message("assistant").write(response)
-
baseline方案设计
2.1 概要设计
baseline基于源大模型的编程能力来解决用户的问题,主要包含一个Streamlit开发的客户端,以及一个部署好浪潮源大模型的服务端。客户端接收到用户请求后,首先进行交互历史拼接,然后输入到服务端的浪潮源大模型,得到模型输出结果后,返回给客户端,用于回复用户的问题。
暂时无法在飞书文档外展示此内容
2.2 详细设计
暂时无法在飞书文档外展示此内容
- 导入库:
- 导入所需要的依赖,包括
transformers,torch和streamlit。其中torch魔搭本身已经安装,transformers和streamlit在第二步也安装完毕。
- 导入所需要的依赖,包括
- 模型下载:
Yuan2-2B-Mars支持通过多个平台进行下载,包括魔搭、HuggingFace、OpenXlab、百度网盘、WiseModel等。因为我们的机器就在魔搭,所以这里我们直接选择通过魔搭进行下载。模型在魔搭平台的地址为 IEITYuan/Yuan2-2B-Mars-hf。
模型下载使用的是 modelscope 中的 snapshot_download 函数,第一个参数为模型名称 IEITYuan/Yuan2-2B-Mars-hf,第二个参数 cache_dir 为模型保存路径,这里.表示当前路径。
模型大小约为4.1G,由于是从魔搭直接进行下载,速度会非常快。下载完成后,会在当前目录增加一个名为 IEITYuan 的文件夹,其中 Yuan2-2B-Mars-hf 里面保存着我们下载好的源大模型。
- 模型加载:
使用 transformers 中的 from_pretrained 函数来加载下载好的模型和tokenizer,并通过 .cuda() 将模型放置在GPU上。另外,这里额外使用了 streamlit 提供的一个装饰器 @st.cache_resource ,它可以用于缓存加载好的模型和tokenizer。
- 读取用户输入:
使用 streamlit 提供的 chat_input() 来获取用户输入,同时将其保存到对话历史里,并通过st.chat_message("user").write(prompt) 在聊天界面上进行显示。
- 对话历史拼接:
对于 Yuan2-2B-Mars 模型来说,输入需要在末尾添加 ,模型输出到 结束。如果输入是多轮对话历史,需要使用 进行拼接,并且在末尾添加。
- 模型调用:
输入的prompt需要先经tokenizer切分成token,并转成对应的id,并通过 .cuda() 将输入也放置在GPU上。然后调用 model.generate() 生成输出的id,并通过 tokenizer.decode() 将id转成对应的字符串。最后从字符串中提取模型生成的内容(即 之后的字符串),并删除末尾的 ,得到最终的回复内容。
- 显示模型输出:
- 得到回复内容后,将其保存到对话历史里,并通过
st.chat_message("assistant").write(response)在聊天界面上进行显示。
- 得到回复内容后,将其保存到对话历史里,并通过
尝试替换其他Yuan大****模型!
https://datawhaler.feishu.cn/sync/UG0ydiJi9sSFkub60HmcuQTJn9f